Types of CS Systems Installations
On This Page
Types of CS Systems Installations¶
Cerebras Wafer-Scale Cluster¶
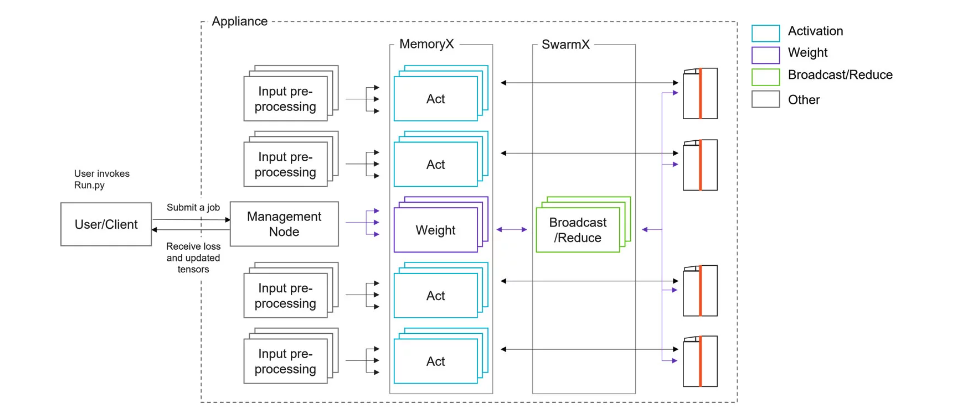
This deployment comprises one or several CS-2 systems, MemoryX and SwarmX technologies, management and input worker nodes. The Cerebras Wafer-Scale cluster is run as a simple appliance. It enables users to scale out their training jobs to multiple CS-2 systems with linear performance scaling in weight-streaming execution mode. Users can also use the pipelined execution mode on a Cerebras Wafer-Scale Cluster.
For more more details, see: What is Appliance Mode?
To train on a cluster of CS-2s using weight streaming, we employ data parallel distribution across CS-2 systems. This means that each batch of training data is sharded into smaller batches, and each CS-2 in the cluster is given a shard, which is a smaller number of example inputs from the training set. We stream the network weights layer by layer, starting with the input layer, from a large capacity memory service called MemoryX, and we broadcast the current layer so that the WSE within each CS-2 has its own copy of the weights. The WSEs compute the output of this layer for their shards. After the loss layer and first gradient computation is done, we repeat the broadcasts of weights layer by layer in the reverse order, and carry out back-propagation. After each layer’s backprop is done, each WSE has its own new weight gradient for the current layer. These are sent into the interconnect fabric, SwarmX, that previously accomplished the broadcast through data replication. SwarmX now provides data aggregation by adding together the weight gradients provided by the WSEs, returning the sum of these weight gradients to MemoryX. MemoryX then implements the weight update due to the batch via the chosen learning algorithm (ADAM, momentum, or another method). This separation of weight storage and learning algorithm from the job of forward and backprop allows us to scale memory capacity to meet the needs of large model sizes, and independently scale the cluster size to meet the compute throughput needs for training rapidly.
The dynamic coordination of the cluster and its CS-2s, the SwarmX nodes, the compute and storage nodes and their worker and coordinator processes that constitute MemoryX are all the responsibility of the Cerebras Appliance Mode software that runs on host system CPU nodes.
In appliance mode, the user’s minimal specification is automatically amplified into commands to assemble resources and deploy software, creating a full parallel training system as shown in the figure. The assembled hardware includes the user-chosen number of CS-2 nodes, custom networking gear (switches, in-network compute) to implement the SwarmX broadcast and reduce network for streaming weights and gradients, compute/network nodes to create MemoryX, with sufficient bandwidth to provide training data batches (the activation servers) and model weights (the weight server or servers), and the data-preprocessing and coordinator nodes to access and supply training data from the file system and to monitor, synchronize, and otherwise direct the activities of these parallel components. Appliance Mode deploys Cerebras software on these assembled resources to run the job.
Original Cerebras Installation¶
This is the Cerebras original installation, consisting of a CS-2 and supporting CPU cluster. This installation is designed for a single CS-2 deployment and can only support the pipelined execution mode. Below is an example diagram of the layout and interaction pattern.
Note
Cerebras is in the process of deprecating the original installation mode and in the future will support only the Appliance mode. If you run the original installation, contact your Cerebras representative.
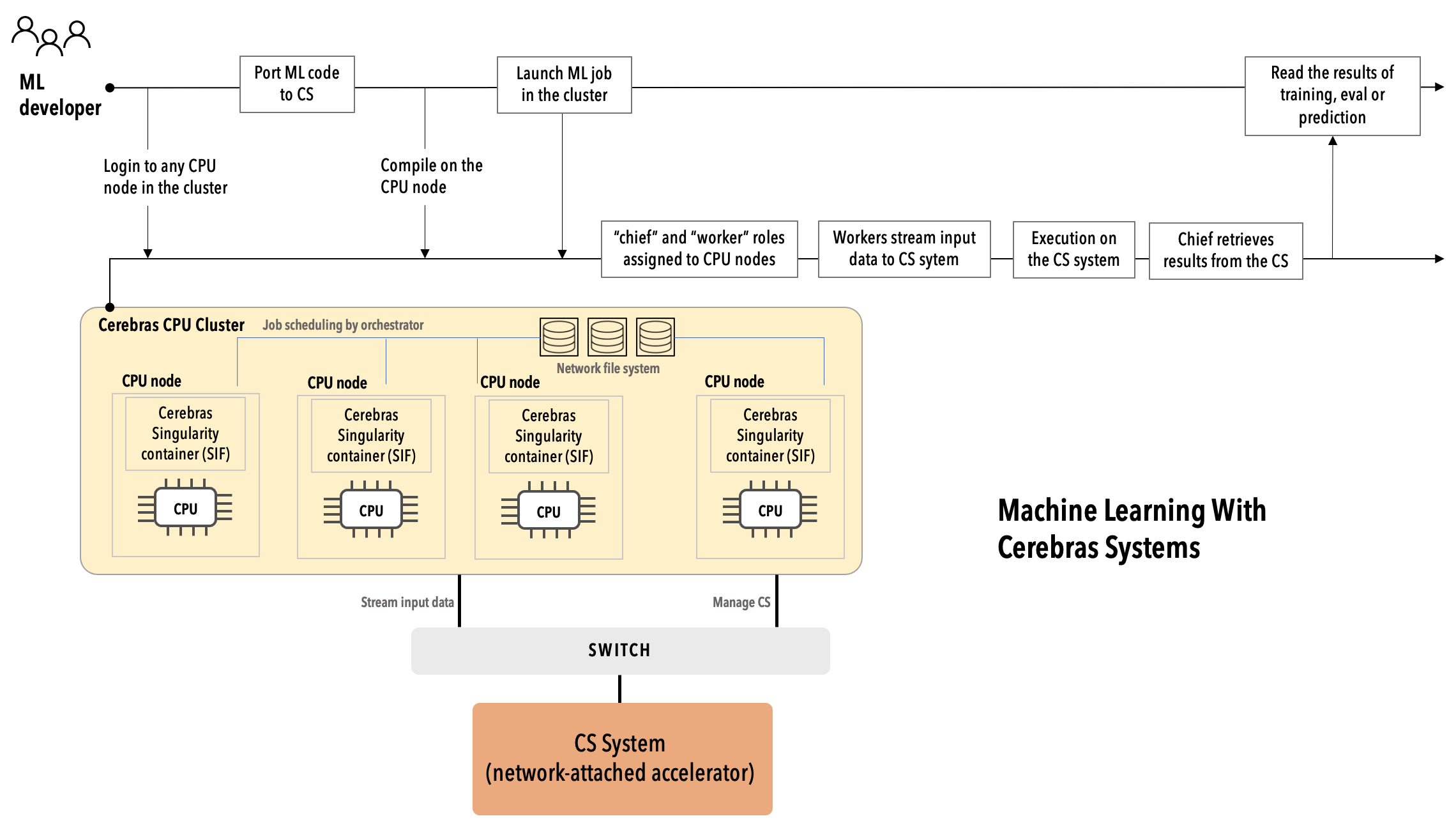
CPU cluster¶
During runtime, the CPU nodes in the Original Cerebras Support Cluster are assigned two distinct roles: a single chief and multiple workers. See the following for a description of these roles.
In the CS system execution model, a CPU node is configured either as a chief node, or as a worker node. There is one chief node and one or more worker nodes.
Chief nodes¶
The chief node compiles the ML model into a Cerebras executable and manages the initialization and training loop on the CS system. Usually, one CPU node is assigned exclusively to the chief role.
Worker¶
The worker node handles the input pipeline and the data streaming to the CS system. One or more CPU nodes are assigned as workers. You can scale worker nodes up or down to provide the desired input bandwidth.