Control numerical precision level#
Note
The Cerebras cluster currently supports only training with mixed precision data types. Ensure your models have float16 or bfloat16 inputs and float32 arithmetic operations. When combined with Train with dynamic loss scaling, mixed precision can result in speedups in training. With bfloat16 training precision, dynamic loss scaling is not required.
Overview#
You have the ability to manage the degree of numerical precision employed during training sessions for large NLP models. This concept might also be labeled as Precision and Optimization Level (POL) in other documentation.
Setting the numerical precision#
Configure the precision_opt_level flag within the .yaml configuration for all models integrated into the Cerebras Model Zoo. You can locate the precision_opt_level flag within the runconfig section.:
runconfig:
precision_opt_level:
...
The functionality of the precision_opt_level flag involves striking a balance between model precision and performance, depending on the numerical setting. In this release:
Setting
precision_opt_levelto 0 utilizes single-precision (float32) accumulations to ensure higher precisionA
precision_opt_levelof 1 represents an optimal tradeoff between precision and performance. It employs float32 reductions in attention and a combination of float32 and bfloat16/float16 reductions in matrix multiplication, thereby enhancing performanceA
precision_opt_levelof 2 is a high-performance setting, combining float32 and bfloat16/float16 reductions in attention and matrix multiplication kernels, along with bfloat16/float16 softmax in attention, delivering the best performance
The default configuration for models in the Cerebras Model Zoo is to have precision_opt_level: 1 with the use of bfloat16, which ensures convergence and aligns with the numerical results achieved by other accelerators.
Note
Cerebras-trained models, like Cerebras-GPT, have been trained using precision_opt_level: 0. This setting is recommended for obtaining the best model performance when the model parameters exceed 6.7 billion.
Additionally, it’s worth noting that precision_opt_level: 2 is primarily used as an internal tool by Cerebras to evaluate the future performance of their hardware.
The CS system offers support for the following data formats:
32-bit floating-point format: This format is IEEE single-precision, commonly known as FP32
16-bit floating-point format: This format is IEEE half-precision, commonly known as FP16
BFloat16: BFloat16 has eight exponent bits and is specifically designed for deep-learning applications
It’s important to note that 16-bit arithmetic in the CS system uses 16-bit words and is always aligned to a 16-bit boundary. On the other hand, single-precision arithmetic uses even-aligned register pairs for register operands and requires 32-bit aligned addresses for memory operands.
Note
In the CS system, memory is 16-bit word addressable. It is not byte addressable, so you cannot directly access individual bytes within a word.
Numerical precisions#
FP32 Single-Precision#
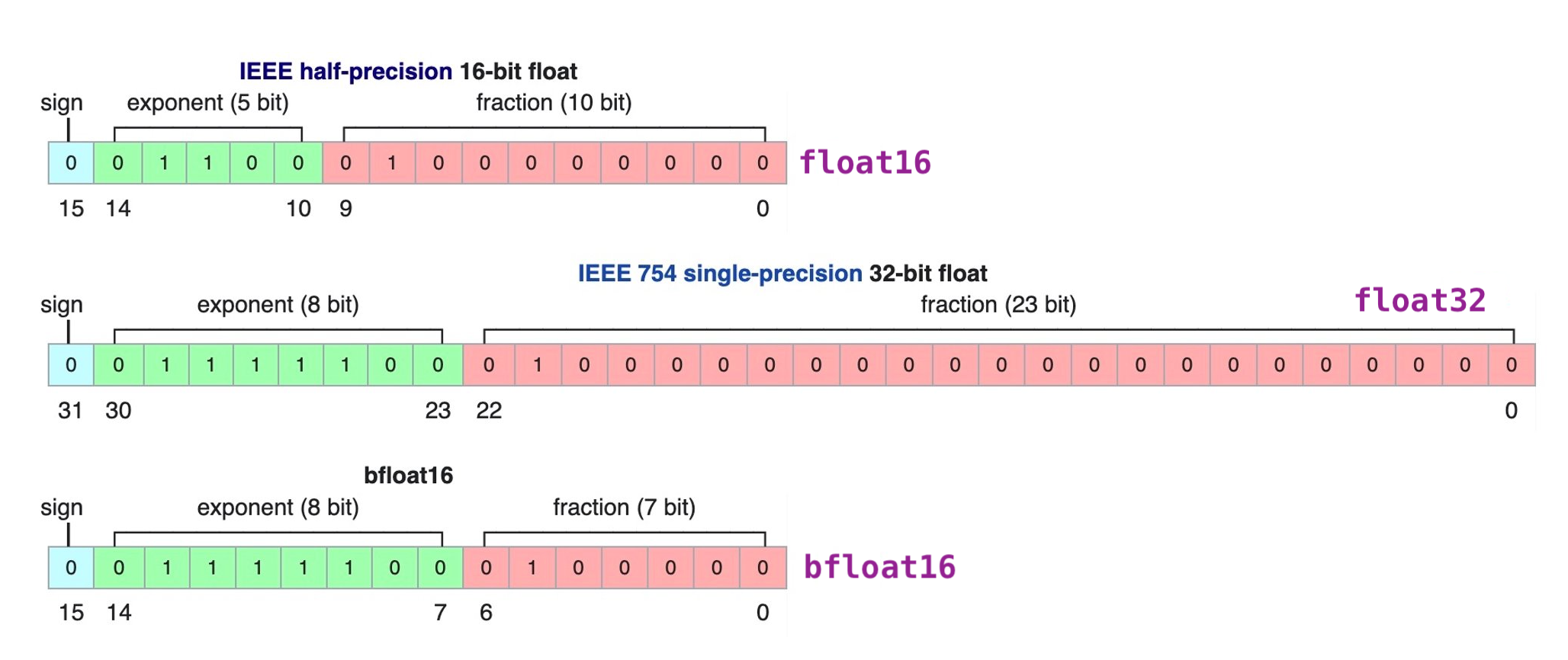
FP32, as used in the CS system, is indeed equivalent to IEEE binary32, which is also known as single-precision floating-point format. In this format, there are 8 bits allocated for the exponent and 23 bits for the explicit mantissa.
Sign: 1 |
Exponent: 8 |
Mantissa: 23 |
FP16#
The FP16 implementation in the CS system adheres to the IEEE standard for binary16, commonly known as half-precision floating-point format. In this format, there are 5 bits reserved for the exponent and 10 bits for the explicit mantissa.
Sign: 1 |
Exponent: 5 |
Mantissa: 10 |
BFloat16 half precision#
This section provides an explanation of the bfloat16-dtype, which is enabled in PyTorch for models like GPT-2, GPT-3, GPT-J, and GPT-neox as part of the automatic mixed precision mode.
Automatic mixed precision is a mode that enables the training of deep learning models using a combination of single-precision floating-point (float32) and half-precision floating-point formats, such as float16 or bfloat16.
The primary advantages of the mixed precision mode are centered on performance. It’s an optimization technique that allows for faster network training without sacrificing quality. This efficiency stems from the fact that some layers within neural networks can be computed with lower precision, such as convolutional or linear layers. These layers have been shown to be significantly faster when executed with float16 or bfloat16. However, certain operations, like reductions, often require a higher precision level to maintain the same level of quality in results.
This trade-off between casting certain operations to half-precision and maintaining others in single precision is part of the “automatic mixed precision algorithm.” In essence, this algorithm assesses the network’s performance in its default precision, then strategically introduces castings to execute the same network with mixed precision settings to optimize performance without compromising accuracy.
It’s important to note that mixed precision doesn’t mandate the use of bfloat16 as a half-precision floating-point format; however, it has demonstrated advantages over using float16. In the following discussion, we’ll delve into bfloat16 in greater detail.
BFloat16 Floating Type#
bfloat16 is a custom 16-bit floating point format for deep learning that’s comprised of one sign bit, eight exponent bits, and seven mantissa bits. This is different from the industry-standard IEEE 16-bit floating point, which was not designed with deep learning applications in mind. The figure below demonstrates the internals of three floating point formats: * float16: IEEE half-precision * float32: IEEE single-precision * bfloat16
We can see that bfloat16 has a greater dynamic range (number of exponent bits) than float16, which is identical to float32.
Experiments: Automatic Mixed Precision and BFloat16#
We experimented a variety of deep learning networks comparing bfloat16 and float16 modes and they yielded valuable insights. It’s clear that bfloat16 offers several advantages:
Performance: Bfloat16 is approximately 18% faster than float16.
Weight Growth: Bfloat16 is significantly less prone to weight growth.
Evaluation Scores: Bfloat16 demonstrates improved evaluation scores.
These findings underscore the benefits of choosing bfloat16 over pure float32 or a mixed version with float16. Bfloat16 enhances training efficiency, conserves memory space, and preserves the same level of accuracy. This is primarily because deep learning models are generally more sensitive to changes in the exponent rather than the mantissa of floating-point numbers.
Furthermore, training with the bfloat16 setting proves to be more robust and less susceptible to issues like underflows, overflows, or other numerical instabilities during training, much like training with pure float32 dtype. This enhanced stability is attributed to the fact that the exponent size of bfloat16 floating point matches that of float32, providing a balance between precision and performance.
How to Enable BFloat16#
To enable bfloat16 in the mixed precision mode, you can make the following changes in the configuration file:
model:
use_bfloat16: True
mixed_precision: True
As you can see, in addition to changes specific to mixed precision and bfloat16 parameter, you need to disable loss scaling. As mentioned, bfloat16 has the same exponent size as float32, thus it will have identical behavioral for underflows, overflows, or any other numeric instability during training. Originally, loss scaling factor was introduced for the mixed precision mode with float16 setting. However, it was necessary to scale the loss to avoid these side effects. bfloat16 does not require loss scaling, thus comes close to being a drop-in replacement for float32 when training and running deep neural networks.
To experiment with networks using this setting, you can refer to the specific references provided for the gpt2, gpt3, and gptj models in the Model Zoo.