The cs_input_analyzer Script#
We recommend that you run the cs_input_analyzer Bash script before running your model on the Cerebras system. This script analyzes your model’s input pipelinedto determine optimal distributed CPU compute resources you need.
Note
This applies only to TensorFlow pipelinedmodels and the Slurm / Singularity Workflow.
CS Input Analyzer Script vs Input Function Analyzer Report
This cs_input_analyzer Bash script is different from the Input Function Report. The Input Function Report is generated automatically during compile time and contains a report on your TensorFlow model’s input function.
The cs_input_analyzer Bash script first compiles your model on the CPU and then analyzes your model’s input pipeline. The script then generates a report containing the recommended Slurm configurations that you should use with the The csrun_wse Script script to train your model on the Cerebras system. The report also contains an estimate of the input performance.
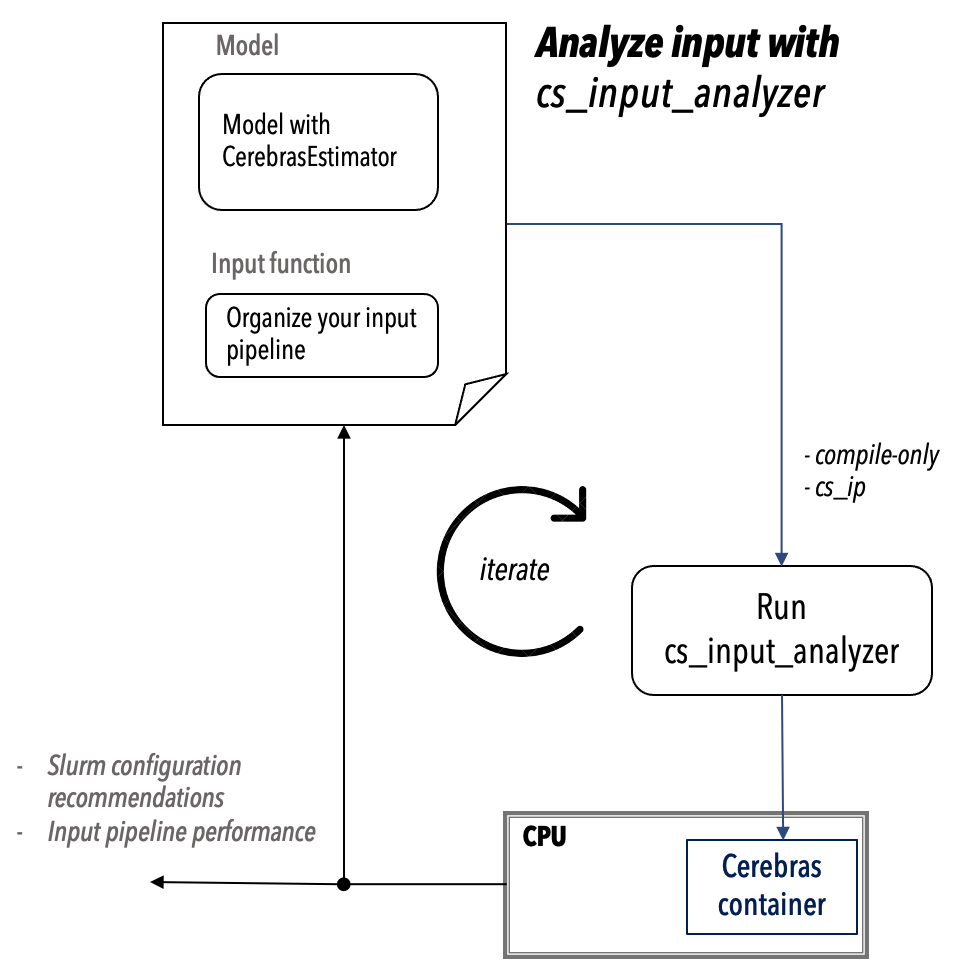
For example:
The following command:
cs_input_analyzer python run.py --mode=train --compile_only
will run compile and then return an input performance estimate.
and the following command:
cs_input_analyzer --available-nodes=3 python run.py --mode=train --validate_only
will run validation and then return an input performance estimate assuming that three nodes are available for training.
Important
All command examples showing command line options for validate, compile or train and so on, for example, python run.py --validate_only, are for the run script run.py written by Cerebras. If you have your own run script, make sure you pass the command line options defined in your run script.
Usage#
$ ./cs_input_analyzer --help
Usage: cs_input_analyzer [--help] [--available-nodes] [--mount-dirs] command_for_validate_compile
...
...
...
Description#
Analyzes your input pipelinedafter completing a compile or validation.
A report containing recommended Slurm configurations for use when running
on the CS system, along with the estimated input performance, is logged at
the end. See the description for the command_for_validate_compile
argument for how to specify full-compile or validate-only options.
To adhere to the recommended Slurm settings printed in the report, you must specify them when calling the The csrun_wse Script script.
Improve performance
The quality of the performance estimates and the generated Slurm settings improves if:
A full-compile is performed instead of validate-only, and
The
cs_ipargument is set in CSRunConfig (generally this can be set in the run.py also).
Important
To ensure consistent results, this script allocates a whole node while executing.
Arguments#
command_for_validate_compile: A Python command to initiate a full-compile or validation-only. For example:python run.py --mode=train --compile_only --cs_ip=0.0.0.0
python run.py --mode=train --validate_only--available-nodes: Optional. Set this to the number of nodes available when executing on the CS system.Note
This value is only used for estimating the performance and generating recommended Slurm configuration. Default is 1.
--mount-dirs: Optional. A string of comma-separated paths to mount in addition to the standard paths listed in thecsrun_cpuscript. Default is an empty string (only the paths listed incsrun_cpuare mounted).See also
For how to list the paths in
csrun_cpu, see The csrun_cpu Script.
Example#
The following command:
cs_input_analyzer --available-nodes=3 python run.py --mode=train --validate_only
Executes the command python run.py --mode=validate_only --cs_ip=0.0.0.0,
which sets the cs_ip in the CSRunConfig and runs the validation inside the
Cerebras container on a CPU node. The input pipelinedperformance is then
analyzed using the validation information to print a performance report.
Note
Providing the
cs_ipenhances the quality of the estimates.
The following command:
cs_input_analyzer --mount-dirs="/data/ml,/lab/ml" python run.py --mode=train --compile_only --cs_ip=0.0.0.0
Mounts /data/ml and /lab/ml in addition to the default mount
directories, and executes the command python run.py --mode=compile_only,
which runs a full compilation inside the Cerebras container on a CPU node. The
input pipelinedperformance is then analyzed using the compile information to
print a performance report and recommended Slurm settings.
Note
Unless the input pipelinedis a bottleneck, the input pipelinedperformance in the report will likely be higher than the actual training performance.