Cerebras Wafer-Scale Cluster#
Overview#
The Cerebras Wafer-Scale Cluster is meticulously engineered to enable the training of neural networks with remarkably efficient linear scaling across millions of cores, all without the complexities of traditional distributed computing.
Fig. 1 illustrates the key components within the cluster:
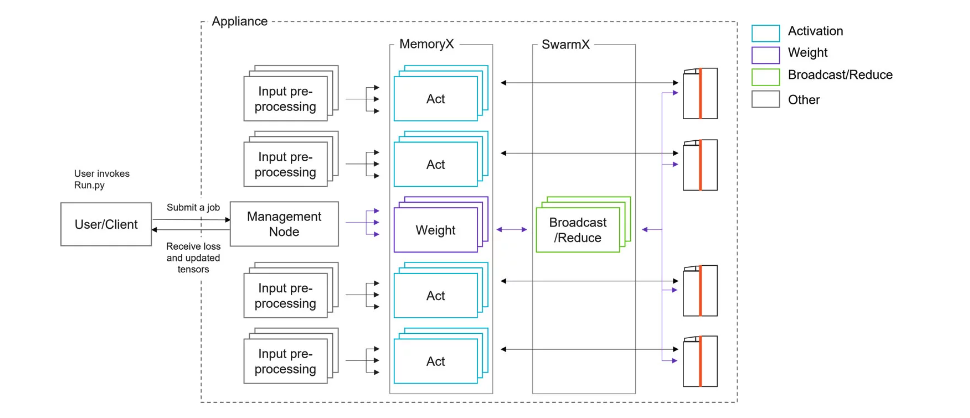
Fig. 1 Topology of Cerebras Wafer-Scale Cluster#
Key components#
CS-3 systems#
The CS-3 systems represents the latest advancement in our lineup, incorporating the innovative WSE-3 (Wafer-Scale Engine 3) to deliver cutting-edge performance. Building on the user-friendly experience of its predecessor, the CS-2, the CS-3 significantly enhances computational efficiency and performance.
This next-gen system introduces a novel instruction set architecture and boosts the SIMD (Single Instruction, Multiple Data) width, providing more parallel processing power. Additionally, it expands the core count by 20% and enhances the ingress/egress bandwidth by 30%, enabling faster data processing and transfer rates.
Compatibility and performance testing are a cornerstone of the CS-3’s development. All models available in the Model Zoo have been verified for functionality on the CS-3 platform. Furthermore, a selection of key models, including GPT-2, GPT-3, LLaMA, Falcon, BTLM, GPT-J, GPT-NeoX, T5, BERT, and PaLI have undergone rigorous testing to ensure both convergence and performance are optimized for the CS-3, guaranteeing a seamless and efficient user experience. You can find more detailed information in the WSE-3 datasheet and explore a virtual tour of the CS-3.
CS-2 systems#
These are the backbone of the cluster, featuring the powerful Wafer-Scale Engine (WSE). Each CS-2 node, mounted on a rack, is responsible for executing the core training and inference computations within a neural network. The CS-2 nodes not only house the WSE but also handle power management, cooling, and data delivery to the WSE. You can find more detailed information in the WSE-2 datasheet datasheet, explore a virtual tour of the CS-2, and delve into the CS-2 white paper for a comprehensive understanding.
MemoryX technology#
MemoryX technology serves as the storage and intelligent streaming solution for a model’s weights, ensuring efficient and timely access for the CS-X systems.
SwarmX technology#
SwarmX technology plays a pivotal role in integrating multiple CS-X nodes into a unified Cerebras cluster. These nodes collaborate seamlessly in training a single model. SwarmX handles the broadcast of weights from MemoryX to the entire cluster and effectively reduces (sums) gradients in the opposite direction, contributing to efficient training processes.
Input preprocessing servers#
Input Preprocessing servers handle the critical task of preprocessing training data, ensuring that it is appropriately prepared before being dispatched to the CS-X systems. This preprocessing step is vital for training, inference, and evaluation.
Management servers#
Management servers are responsible for orchestrating and scheduling the cluster’s resources, ensuring efficient utilization and coordination among all components in the Cerebras cluster. They play a key role in optimizing the cluster’s performance and resource allocation.
Working with the Cerebras Cluster#
After developing your code, you can initiate the process of submitting it for both training and evaluation from a user node. It’s important to note that the user node operates independently from the cluster and connects to the Cerebras cluster through the management server, as illustrated in Fig. 1. The management server is responsible for handling all resource scheduling. Therefore, your main task is to specify the number of CS-X systems you wish to allocate for either training or evaluation. This enables you to efficiently utilize the Cerebras cluster’s resources without directly managing the intricacies of cluster allocation.
For documentation related to the installation and administration of the Cerebras Wafer-Scale cluster, visit Cerebras deployment documentation.