Multi-Replica Data Parallel Training#
With this feature, the Cerebras compiler uses several copies (replicas) of the same model to run data parallel training. This is similar to how multiple GPUs are used to accelerate training of a single model.
In the background, the compiler ensures that these replicas are initialized with the same weights, and during the training, the weights across all replicas are synchronized after every batch.
A single trained model is available at the conclusion of multi-replica data parallel training. This multi-replica data parallel feature can be used only for training the model.
How it works#
Normal training#
First, the following diagram shows a normal, non-replica model training flow:
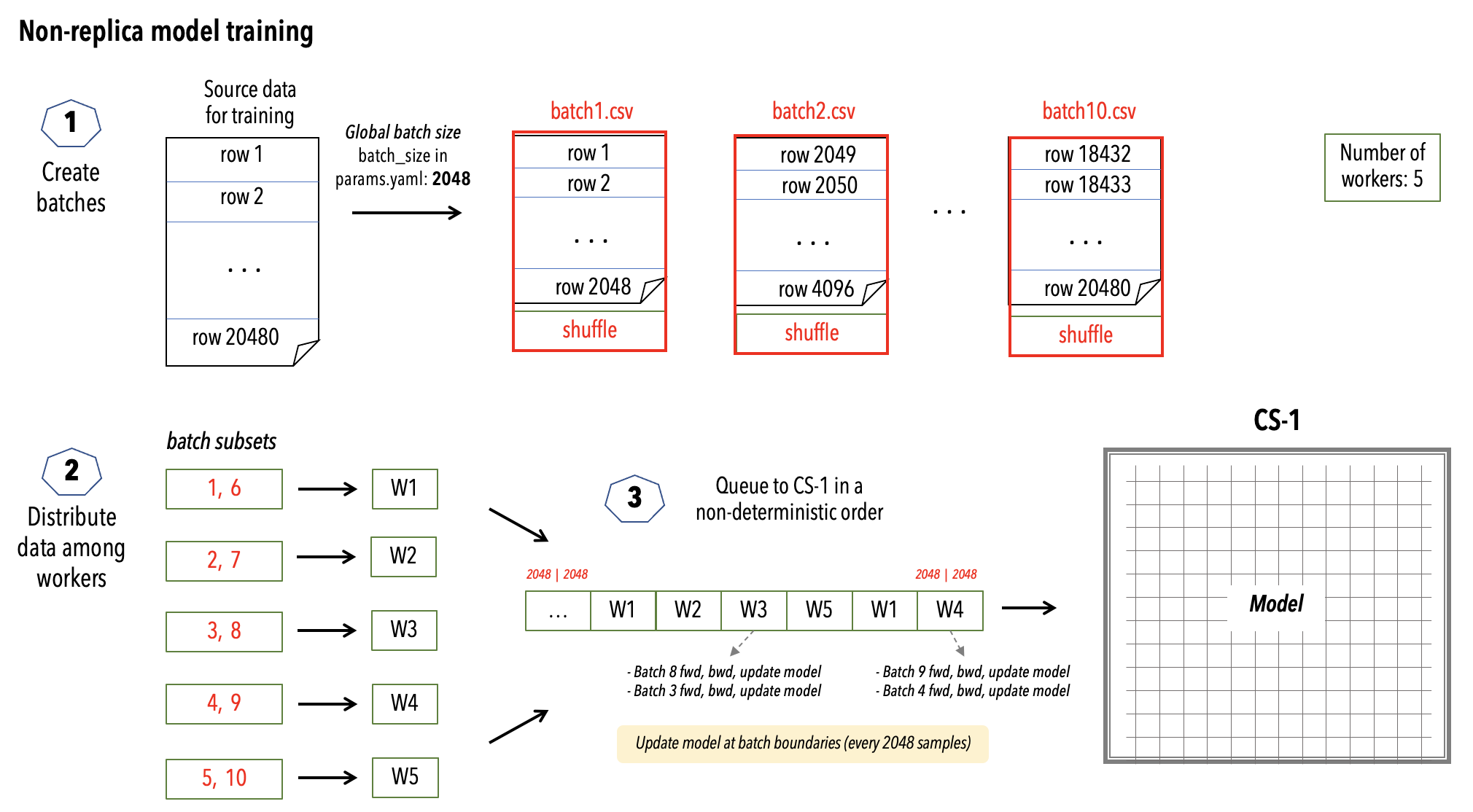
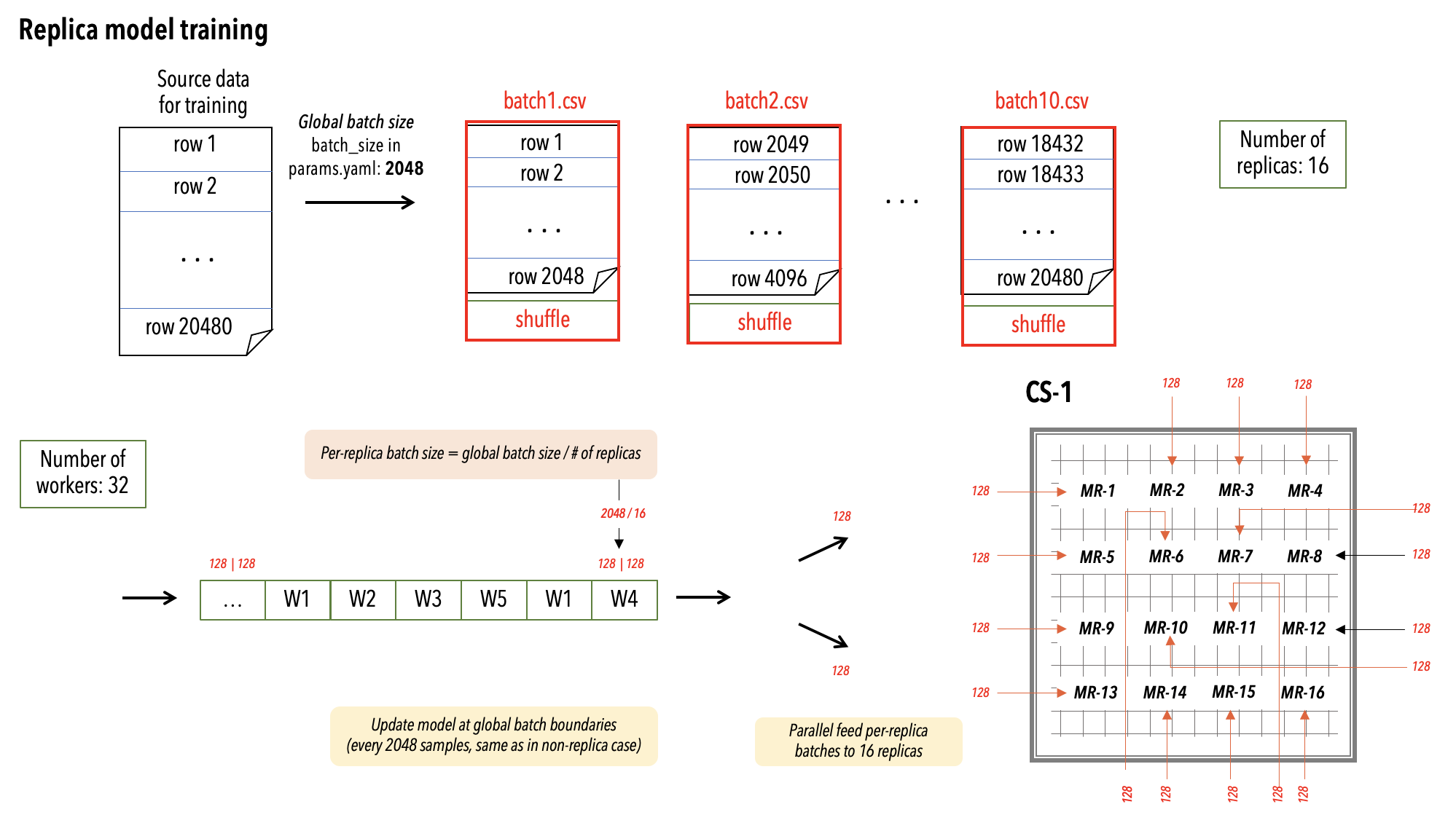
Next, the following diagram shows the multi-replica data parallel training flow:
Multi-replica data parallel training#
In the below diagram, 16 replicas (model replicas MR-1 through MR-16) are trained on the CS system.
Attention
Multi-replica data parallel mode is currently only supported for the training.
Input data streaming#
In the multi-replica data parallel training, the number of replicas is determined by the compiler and cannot be set by the user. In addition, the per-replica-batch-size is derived from the number of replicas, and this per-replica-batch-size is used in the input function for the individual replicas. The compiler automatically does this.
The CerebrasEstimator automatically assigns each worker to each replica in a round-robin fashion. For
example (refer to the diagram in Multi-replica data parallel training section):
If you have two workers and two replicas, then worker one is assigned to replica one, and worker two is assigned to replica two.
If you have three workers and two replicas, then worker one is assigned to replica one, worker two is assigned to replica two, and worker three is assigned to replica one, and so on.
Note
At least N workers are needed for a model with N replicas; otherwise, the execution errors out. For better performance, we recommend using two workers per replica.
Losses#
The losses computed by the individual replicas are combined together and sent to the chief as a single loss
quantity. The CerebrasEstimator receives this single loss in the same way as in a normal, non-replica, training.
Checkpoints#
The multi-replica data parallel training supports checkpoints during mid-training. You can specify a desired number
for the save_checkpoints_steps in params.yaml config file.
See also the Using the CerebrasEstimator documentation section.
Supported models in TensorFlow#
FC-MNIST
BERT
Transformer (AIAYN)
T5
GPT2
Enabling multi-replica data parallel training in TensorFlow#
You can enable the multi-replica data parallel training feature in two ways:
1. In the params.yaml config file, set the multireplica key value to True. See a partial sample
of an example params.yaml file below:
runconfig: max_steps: 100000 save_summary_steps: 500 save_checkpoints_steps: 10000 keep_checkpoint_max: 2 model_dir: 'model_dir' cs_ip: 10.4.5.3 mode: 'train' multireplica: TrueAttention
The default setting is:
multireplica: False.
Or you can use the command line option
--multireplicawhile runningrun.py. For example:csrun_wse python run.py --mode=train --multireplica --cs_ip=10.4.5.3
Supported models in PyTorch#
FC-MNIST
BERT
Transformer (AIAYN)
T5
Enabling multi-replica data parallel training in PyTorch#
You can enable the multi-replica data parallel training feature in much the same manner as Tensorflow:
You can use the command line option
--multireplicawhile runningrun.py. For example:csrun_wse python run.py --mode=train --multireplica --cs_ip=10.4.5.3
The default setting is:
multireplica: False.