Optimize Performance with Automatic Microbatching#
Overview#
This page describes how to configure the Trainer
with automatic microbatching.
Microbatching is an optimization technique that reduces per-system memory usage and improves performance by dividing the global batch size into smaller sub-batches that can be run individually. The gradients from each microbatch are then accumulated before the weight update, so the model still operates on the total global batch size. Even if there are no gradients (i.e. non-training runs), microbatching is a valid technique that you can still utilize to improve performance.
By following this guide, you will be comfortable in configuring a specific microbatch size and Cerebras’ automatic microbatching feature
using the Trainer for any model.
Prerequisites#
Make sure to have read through Trainer Overview and Trainer Configuration Overview which provide a basic overview of how to configure the Trainer and the YAML run Model Zoo models. In this document, you will be using the tools and configurations outlined in those pages.
If you already have an understanding about microbatching background and terminology, please feel free to skip ahead to Configure Microbatching.
Key Terms and Parameters#
num_csx This YAML parameter specifies the number of Cerebras CS-X systems (e.g. CS-2s, CS-3s, etc) that are being used for the model run.
batch_size This YAML parameter specifies the global batch size of the model before the model is split along the batch dimension across
num_csxsystems or into micro batches.Per-system batch size This term is defined implicitly as
⌈batch_size / num_csx⌉and represents the size of the batch used on each Cerebras system.micro_batch_size This YAML parameter controls the micro-batch size that will be used on each Cerebras system.
Warning
The batch_size parameter cannot be smaller than the num_csx parameter.
Background#
Splitting model training or evaluation along the batch dimension into smaller micro batches enables the model to run with larger batch sizes than can physically fit on available device memory. The Cerebras software stack supports automatic microbatching for transformer models without requiring changes to model code. The Cerebras software can also automatically find performant values of micro-batch size.
As illustrated in Fig. 10, a batch size exceeding the device memory capacity can be divided into smaller micro batches. Each micro batch is computed separately, and the resulting gradients are accumulated across micro batches before the final update to the network weights occurs. Statistics like loss can be combined across micro-batches in a similar way. This way, microbatching emulates a bigger batch size by running multiple smaller micro-batches and combining the results.
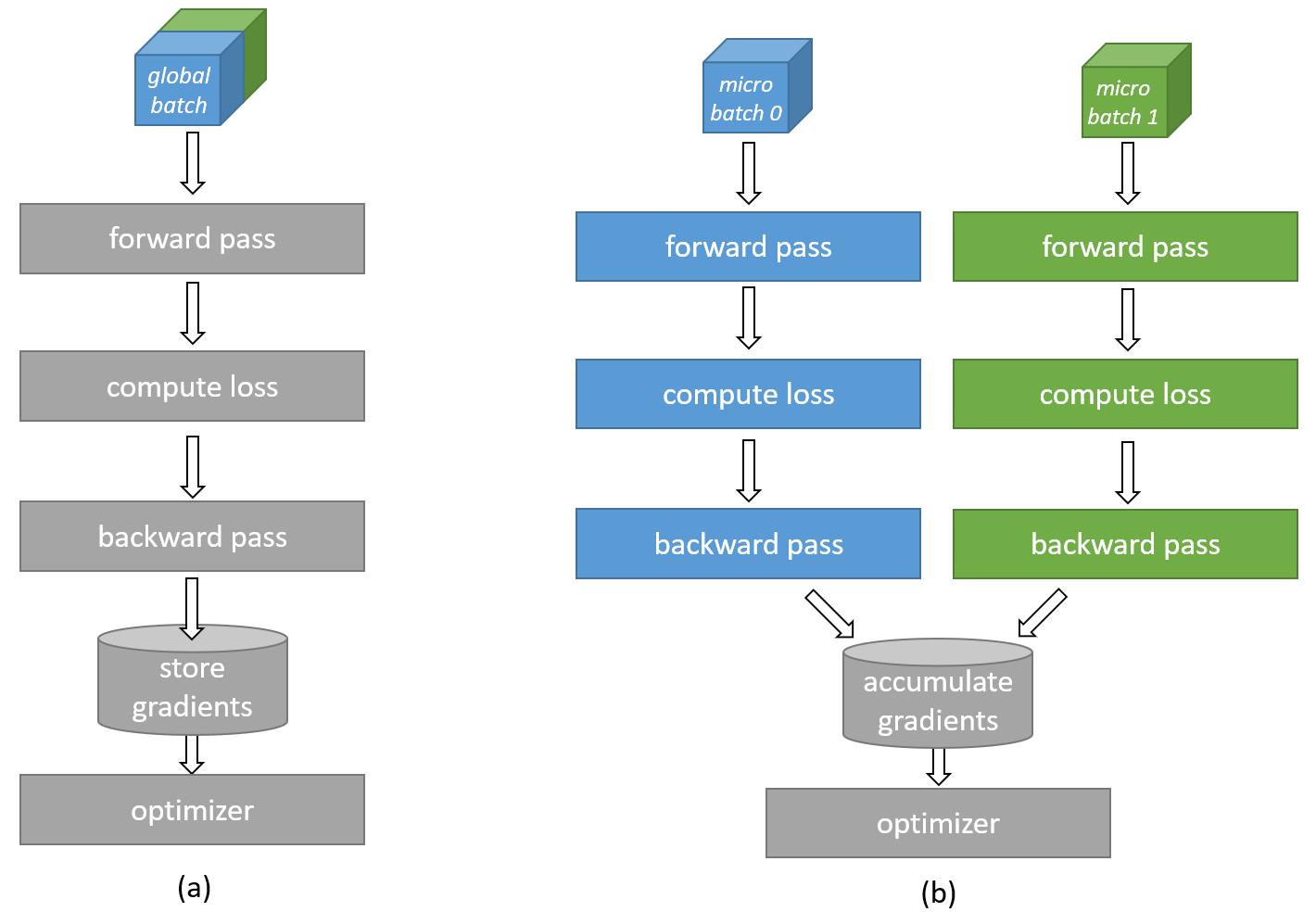
Fig. 10 Tiling and accumulation of gradients along the batch dimension.#
This feature supports an arbitrary global batch size, ensuring an approximately even distribution of the global batch across CS-X systems, even when the batch_size parameter is not divisible by num_csx. It also ensures even distribution across microbatching steps, even when the per-system batch size is not divisible by micro_batch_size. Consequently, there is no need to change the global batch size when scaling the number of Cerebras CS-X systems up or down.
This behaviour is controlled via the micro_batch_size parameter in the YAML config file, as described below.
Configure Microbatching#
This page will present the YAML configuration file as well as the equivalent pure Python setup side-by-side for your
ease of comparison. To configure microbatch settings, you will utilize either the GlobalFlags, ScopedTrainFlags or ScopedValidateFlags callback
to set the performance flag csx.performance.micro_batch_size for microbatching.
Scoping#
If you set the micro-batch size value via GlobalFlags callback, the setting will affect all runs.
However, if you wish to constrain the scope such that the micro-batch size setting affects training runs only, then use the ScopedTrainFlags callback.
In this example, let’s use a cluster with two CSX systems to configure a training run only with the specific microbatch size value of “2”:
The global batch size of “12” will be split between two CS-X systems into a per-box batch size of “6”, and each CS-X will process this via micro-batches of size “2”.
You can manually set this micro-batch value or have the Cerebras compiler automatically determine a reasonable value for you via the auto setting, or find a near-optimal performant value via the explore setting.
Both automatic options, while convenient, will result in a longer compile time; because of this, we recommend using auto and explore to find a good setting and then manually setting this for subsequent experiments.
The range of settings for micro_batch_size are described in detail below:
auto (default): Automatically choose a reasonable micro-batch size. With this setting, the compiler will drop the model to a smaller micro-batch size (which will evenly divide
batch_size / num_csx) if the original batch size per CS-X system does not fit into device memory or the compiler estimates that a lower micro-batch will achieve significantly better samples/second performance. This setting may incur a high compile time due to the search for a satisfactory micro-batch size. Compared to the “explore” setting, “auto” incurs less compile time penalty but can pick sub-optimal micro-batch values. This is the default value ifmicro_batch_sizeis not specified.explore: This setting performs an exhaustive search for a near-optimal micro-batch size. Because this mode can take several hours to run, it can only be specified in
compile_onlymode. Note that this is different from the “auto” setting of micro_batch_size, which tries to find a reasonable micro-batch size selection without too large an increase of compile time. Also, unlike the “auto” setting, “explore” considers all micro-batch sizes and is not restricted bybatch_size/num_csxdivisibility constraints. You can generally expect higher-quality selection of micro-batch size values with"explore"at the expense of a longer compilation run. See Using “explore” to Search for a Near-Optimal Microbatch Size for more information.<positive_int>: You can manually set the explicit micro-batch size for the compiler to use. We recommend setting this parameter if you have a well-informed understanding of an optimal micro-batch size, as it will significantly reduce compile time. The compiler may slightly modify the specified micro-batch size if it is not divisible by the per-box batch size (
⌈batch_size / num_csx⌉) to ensure an approximately even distribution of the global batch across CS-X systems and microbatching steps. A user message will be provided if this adjustment occurs.none: Disable microbatching and use the global
batch_sizeparameter as the micro-batch size. This may result in the model with the given batch size being too large to fit into device memory, in which case compilation will fail. If it does fit, however, the chosen batch size may be suboptimal for performance.
Note
Model performance is a function of the micro-batch size used on a Cerebras system. For example, for a given model a micro-batch of “2” will perform equally well regardless of the values used for num_csx or the global batch_size (as long as batch_size / num_csx is a multiple of the micro-batch size).
Note
The microbatching feature will auto-disable for models that it does not support even if micro_batch_size is set. This includes models using batch normalization, or other kinds of non-linear computation over the batch dimension.
Note
For the example above, since the scope is limited to training, the micro-batch size will be restored to its previous value after training is completed.
In order to apply the micro-batch size setting to validation runs only, please similarly
configure the cerebras.modelzoo.trainer.callbacks.ScopedValidateFlags callback in
the Trainer. An example is as follows:
If you wish to apply the micro-batch size setting to all runs, please use the GlobalFlags callback as such:
Jointly Setting “batch_size” and “micro_batch_size”#
The Cerebras compiler requires that the per-system batch size, batch_size / num_csx, be evenly divisible by the micro-batch size. Therefore, if you are setting micro-batch size explicitly via micro_batch_size: <positive_int>, you must set the global batch size parameter batch_size to be a mutiple of micro_batch_size * num_csx.
If you set micro_batch_size: auto, be aware that the compiler’s choice of microbatch will be restricted to values that evenly divide batch_size/num_csx, and may be less performant than explicitly setting a microbatch size based on the explore flow.
Using “explore” to Search for a Near-Optimal Microbatch Size#
In addition to reducing model memory usage, selecting an effective explicit micro_batch_size can significantly improve model performance. However, finding a good micro_batch_size can be a cumbersome process. Cerebras’ Automatic Batch Exploration (CABE) tool provides a convenient way to select the best performing micro_batch_size.
Procedure#
To enable Automatic Batch Exploration, modify the Trainer configuration for your model in the YAML or Python by setting the following parameters:
1. Set the num_csx and batch_size parameters. These parameters are needed to guide the compiler stack as an initial data point, but their values do not impact the micro_batch_size recommended by the flow. This batch size can be same as the default batch size defined in Model Zoo for the model.
2. Set csx.performance.micro_batch_size performance flag to “explore” via the GlobalFlags, ScopedTrainFlags, or ScopedValidateFlags callbacks depending on the scoping you desire. The example below works with global scoping:
3. If you have a specific range in mind for acceptable micro-batch sizes, you can define a batch exploration range to limit the search space and get to a set of recommended options more quickly. You can specify this range by providing either one or both of the bounds as follows:
4. Finally, launch a compile_only run to start exploration (set compile_only in under the backend configuration of the Trainer).
Expected Output#
As the flow explores the micro-batch vs. performance search space, it recommends interim performant micro-batch sizes. This approach saves time and effort while ensuring near-optimal performance.
Each performance estimate for a recommended micro_batch_size is compared relative to the base performance set by the first recommendation. In the example above, line 2, which recommends micro_batch_size: 2, is estimating that this option is likely to provide 1.20x the performance of micro_batch_size: 1, which is used as the baseline for this run of the tool.
After selecting a micro_batch_size and setting batch_size according to Jointly Setting “batch_size” and “micro_batch_size”, you may launch either a compile-only run or a full training run as needed.
The batch size recommended by CABE is specific to the current model configuration and may require adjustments if there are any changes to the model’s performance-affecting parameters. For instance, altering the model’s operation to evaluation mode or modifying the hidden size could impact performance. In such scenarios, it’s advisable to rerun CABE to ensure the batch size is optimized for the new configuration.
Effective Microbatching Examples#
Below is a suggested list of micro-batch sizes that have demonstrated good performance, primarily with GPT-3 models. These sizes can also serve as useful estimates for other similar-sized GPT-style models, such as BLOOM and LLaMA.
Model Family |
Model Size (Params) |
Micro Batch Size (MBS) |
|---|---|---|
GPT-3 |
1.3B |
253 |
GPT-3 |
2.7B |
198 |
GPT-3 |
6.7B |
121 |
GPT-3 |
13B |
99 |
GPT-3 |
20B |
77 |
GPT-3 |
30B |
69 |
GPT-3 |
39B |
55 |
GPT-3 |
65B |
55 |
GPT-3 |
82B |
48 |
GPT-3 |
175B |
35 |
T5 |
3B |
256 |
T5 |
11B |
520 |
Known issues and limitations#
The current known limitations of automatic microbatching include:
Microbatching has been thoroughly tested mainly with transformer models. The technique is not compatible with models that incorporate batch normalization or layers that execute non-linear computations across batches.
The functionality of Automatic Batch Exploration is confined to transformer models. Attempting to apply it to vision networks, such as CNNs, will result in a runtime error.
To circumvent extended compile times, it’s advisable to directly assign a known effective value to the
micro_batch_sizeparameter instead of leaving it undefined.Enabling Automatic Batch Exploration by setting
micro_batch_sizeto “explore” initiates an exhaustive search, potentially extending over several hours. However, the typical compile time for most GPT models is expected to be around one hour.
Conclusion#
Optimizing performance with automatic microbatching provides a sophisticated approach to enhancing model performance and efficiency, particularly for transformer models. By leveraging this feature and automatic batch exploration, users can navigate the constraints of device memory and improve computational throughput. The provided guidelines and parameters offer a structured way to implement these techniques, ensuring models are not only feasible within hardware limitations but also optimized for peak performance. While the process comes with its own set of limitations and considerations—particularly around microbatching’s compatibility and the scope of Automatic Batch Exploration—the benefits in terms of performance optimization are substantial. Adopting these strategies can lead to more efficient and effective model training, ultimately accelerating the path to achieving robust and scalable AI solutions.