Train with gradient accumulation#
Note
Gradient accumulation is only available for transformer models in weight-streaming execution.
Gradient accumulation is a technique that allows training with larger effective batch sizes than can physically fit in the available device memory. As illustrated in Fig. 10, a batch size exceeding the device memory capacity can be divided into smaller sub-batches (minibatches). Each sub-batch is computed separately, and the resulting gradients are accumulated across sub-batches before the final update to the network weights occurs. This way, gradient accumulation emulates a bigger batch size by running multiple smaller sub-batches and combining the results.
If gradient accumulation is enabled, the compiler will drop the model to a smaller sub-batch size either if the original batch size does not fit into device memory or the compiler estimates that a lower sub-batch will achieve significantly better samples/second performance.
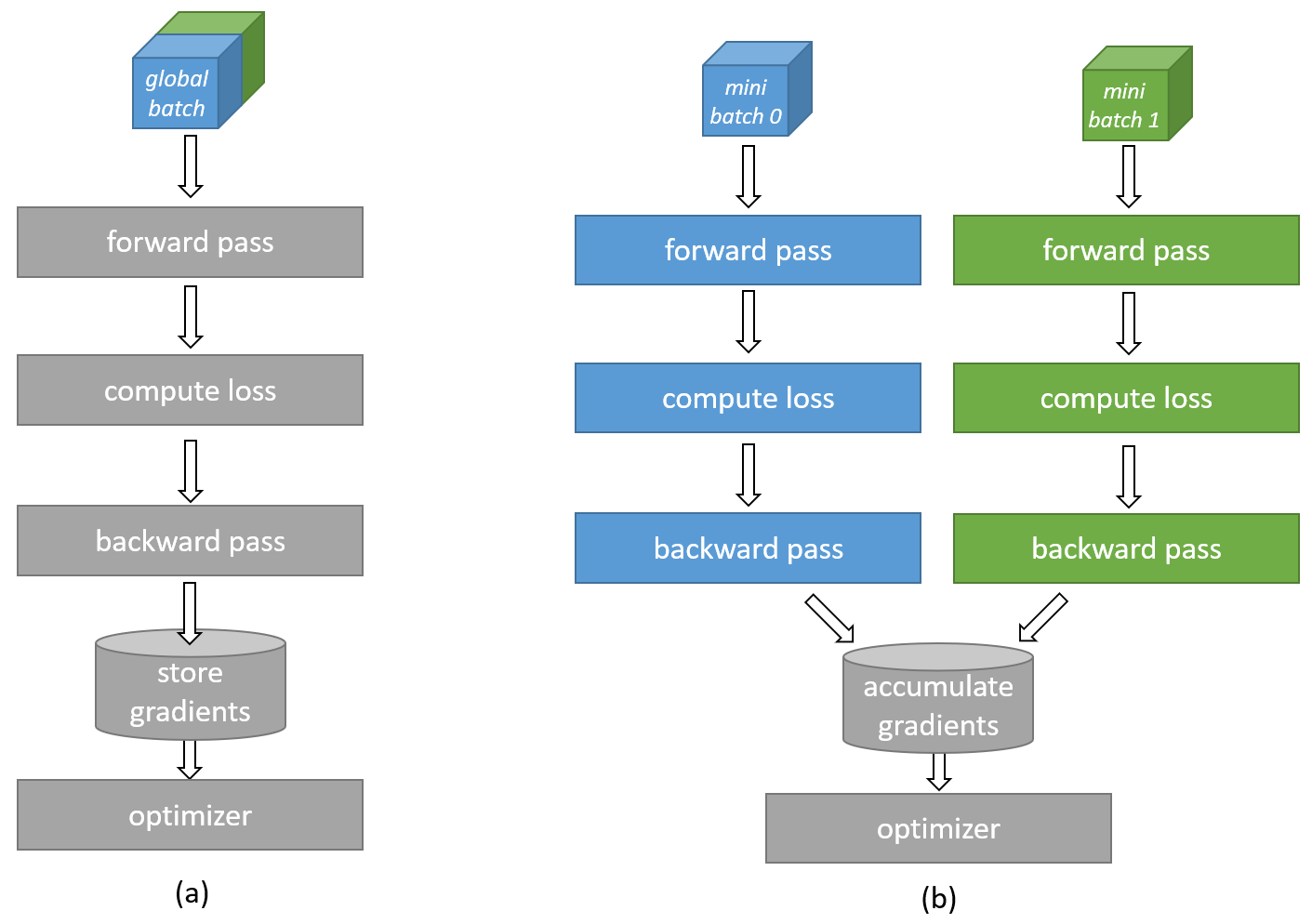
Fig. 10 Gradient accumulation computation#
How to enable#
To enable gradient accumulation, set use_cs_grad_accum: True in the runconfig section of the model params yaml file.
The software stack will automatically choose an appropriate sub-batch size that cleanly divides the batch size, users are not expected to manually choose a sub-batch size.
Known issues and limitations#
The current known limitations include:
Vision models (CNNs) are not supported.
Batch normalization is not supported.
Support is limited to networks whose gradients and statistics can be accumulated across sub-batches.
Gradient accumulation support for T5 model is experimental and you may experience extended compilation times.
The compiler selects the largest sub-batch size that can be compiled and evenly divides the original model batch size.