Train with weight sparsity#
Note
Sparsity support in Cerebras Model Zoo is under development. All sparsity features are only supported for PyTorch models running in Weight Streaming execution.
In 2018, state-of-the-art neural networks such as BERT had a few hundred million parameters. Two years later, GPT-3 was announced. With 175 billion parameters and a 3.14*1023 FLOPs (floating point operations) compute budget, it is estimated to have required 10,000 NVIDIA V100 GPUs for 15 days, accounting for 552 tons of CO2e emissions and 1,287 MWh of energy [Patterson et al.].
While model sizes continue to increase in pursuit of better accuracy, the resulting compute and memory requirements make these models intractable for most practitioners. Weight sparsity, when coupled with hardware which accelerates unstructured sparsity, is a promising way to train models using significantly less compute and memory.

Weight sparse training methods set subsets of weights to zero during training, often the ones already close to zero in magnitude. The resulting sparse model requires far fewer FLOPs to train and fewer parameters to store, as multiplies with zeros can be skipped on both forward and backward passes through the network. Only systems that can accelerate sparsity, such as Cerebras CS-2, can take advantage of the lower resource requirement and use the reduction in FLOPs to significantly accelerate training. Finding and training sparse models to match the accuracy of their original “dense” (i.e. non-sparse) configurations is an active and open area of research! For software release 1.8, we are exposing an early preview static sparsity mechanism to allow experimentation with this exciting capability.
Static Sparsity via YAML#
In the Cerebras stack, runs are parameterized via YAML configs that include model, data, and optimizer parameters (GPT-3 example here). To train with sparsity, include a sparsity section in your run’s YAML config file as a sibling to the model and optimizer section.
sparsity:
sparsity: 0.3
init_method: "random"
seed: 1234
Each layer is independently sparsified prior to starting training. As an example, if the sparsity level is set to 0.3 (30%) and init_method is “random”, a randomly chosen 30% of weights for each layer will be sparsified. Sparse weights remain sparse for the entire duration of training (“static sparsity”). To change sparsity levels, training will need to be re-started.
The sparsity config is parameterized by:
sparsity: the desired sparsity level between 0 and 1.init_method: the type of sparsification (randomortopk). Inrandom, weights are sparsified randomly, while intopk, the weights with the lowest magnitude are sparsified.seed: optional numpy seed. Seeds determining layer specific sparsity patterns are derived from this base seed. As long as it is fixed, sparsification routines that involve randomness will be “random” but deterministically so.param_name_patterns: optional parameter to specify which layers to sparsify. Any regex provided here will be matched to layer names and if it appears in the layer name, that layer will be sparsified. For fine-grained control,param_name_patternscan also be a dict, allowing per-layer sparsity values, init methods, and seeds. To determine names of different layers, load an existing checkpoint or start a dense run and inspect the initial checkpoint (see guide: Work with Cerebras checkpoints).
Unless otherwise specified by param_name_patterns, we do not sparsify weights with embedding, norm, or lm_head in their name or one dimensional weights such as biases.
Config examples:
sparsity:
sparsity: 0.3
init_method: "topk"
param_name_patterns: "ffn.*weight"
seed: 1234
sparsity:
sparsity: 0.9
init_method: "topk"
param_name_patterns:
- "dense_layer.weight"
- "linear_layer.weight"
seed: 1234
sparsity:
init_method: "topk"
seed: 1234
param_name_patterns:
ffn.*weight:
sparsity: 0.3
attn.*weight:
sparsity: 0.4
For users who would like to modify how weights are sparsified or inspect how random and topk sparsification is implemented, please see here.
Internally, Cerebras represents sparse tensors using CSR (compressed sparse row) format and our dataflow hardware automatically skips computations on sparse weights. To make it easy to use standard models written for dense tensors, we keep weights and checkpoints as they are, but mark sparse weights in-place using a sentinel value (NaN). The result of a sparse run is thus a standard checkpoint with this sentinel value used in replacement of sparse weights.
Running a Sparse Model#
No change is needed to the run command (see guide: Launch your job) - just make sure the .yaml being used has sparsity enabled. If you want to validate your sparsity config prior to launching training, run with --validate_only. You can also log which weights are being sparsified by passing --logging DEBUG to your run command.
python run.py CSX weight_streaming \
--params params_with_sparsity.yaml \
--num_csx=1 \
--model_dir model_dir --mode {train,eval,eval_all,train_and_eval} \
--mount_dirs {paths modelzoo and to data} \
--python_paths {paths to modelzoo and other python code if used}
To run a workload like iterative magnitude pruning, change the sparsity in the params file after a checkpoint is taken and rerun with the new sparsity value.
Checkpoint Format#
To “finalize” a checkpoint from a sparse run (i.e. replace the sentinel value with 0) for further dense training, please use this conversion utility. Example:
python finalizer.py --input <input_checkpoint.mdl> --output <output_checkpoint.mdl>
This script imports modelzoo - to use it, you may need to append the location of your modelzoo to your PYTHONPATH. Once finalized, the checkpoint is like any other standard checkpoint and contains no information about previous sparsity patterns.
When using our checkpoint convertor (see guide: Convert checkpoints & configurations between Hugging Face and Cerebras Model Zoo, and between Cerebras software releases) to convert to Huggingface, finalization is done automatically.
Note: if training from scratch, sparsification will be based on the weights at initialization. If beginning from a checkpoint, sparsification will be applied based on checkpoint weights. However, if training from a checkpoint from a sparse run (that already has sentinel values), sparsity will be increased or decreased to reach the specified level. For example, if the config specifies a lower sparsity level than currently present in the checkpoint, some previously sparse weights will be randomly “regrown” (and initialized to 0.0). If the config specifies a higher sparsity level, all previously sparse weights will still be treated as sparse and some previously trained weights will be set to sparse to meet the new sparsity level.
To train sparse, it is not enough to use a checkpoint with the sentinel value in place of sparse weights, there must be a corresponding sparsity section in the YAML.
Research with Sparsity#
Sparsity is a powerful tool that can improve performance, reduce model size, and help generalizability while achieving the same accuracy as densely trained models. Read some of our research work on training with sparsity here:
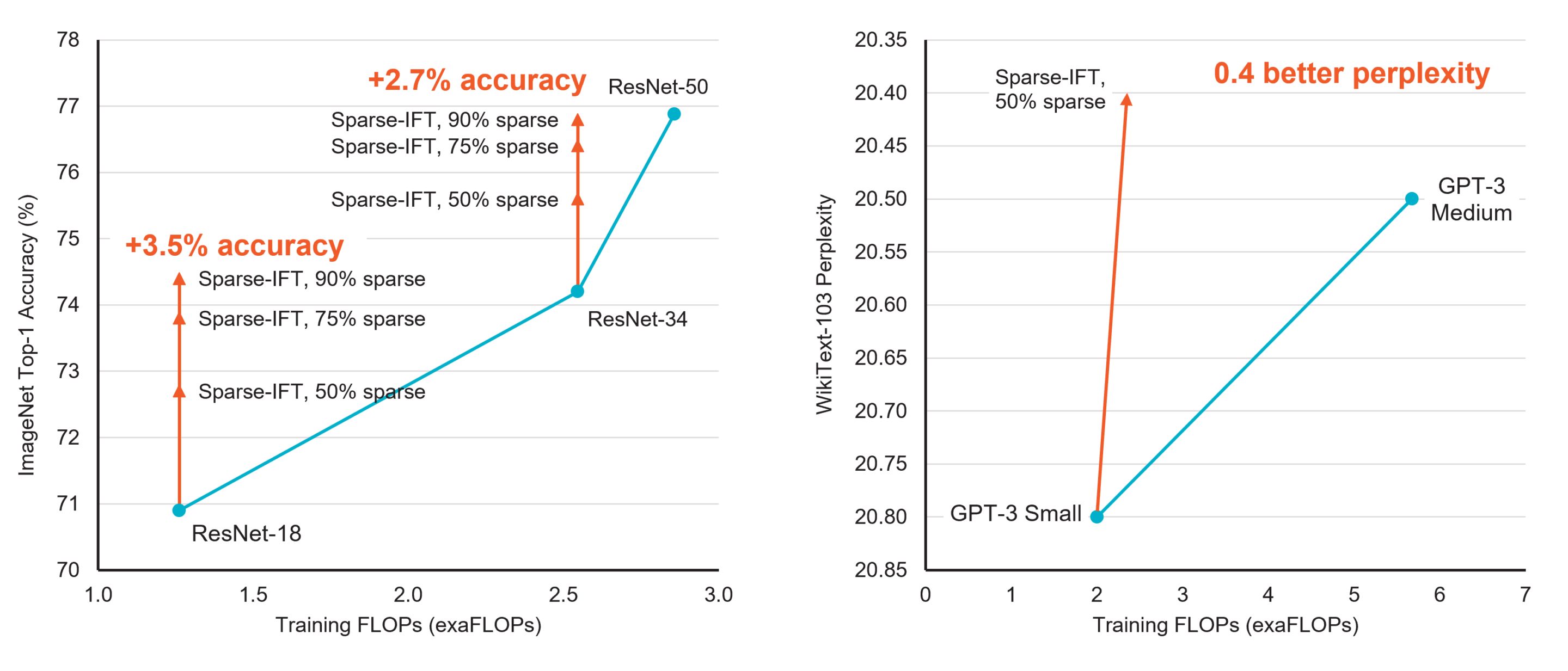
Sparse pre-training and dense fine-tuning (SPDF): blog, arxiv. In this work, we show how we can pre-train a 1.3B parameter GPT-3 style model with up to 75% unstructured sparsity and 60% fewer training FLOPs on Cerebras CS-2, without a significant loss in accuracy on downstream tasks.
Sparse Iso-FLOP transformations for Maximizing Training Efficiency (Sparse-IFT): blog, arxiv. In this work, we show how pre-training a GPT-3 style small model with sparsity leads to a 0.4 perplexity improvement on the WikiText103 language modeling task. See table below and paper for more details, including results on computer vision tasks.
Tutorials to reproduce results coming soon!
Implementation Notes#
The ability to specify dynamic sparsity with explicit masks on CS2 in PyTorch is still under development, so inband masks with sentinels are only a temporary solution for the 1.8 preview of sparsity. The YAML configs will be forward compatible with static sparsity on future releases.
Note, PyTorch does have mechanisms for both representing sparse tensors and utilities for pruning networks. However, sparse tensors require custom kernels to operate on and have lower compatibility with existing models and utilities. In particular, a torch.nn.Parameter can not hold a torch.sparse.tensor without workarounds. The torch.prune utilities are convenient, but the asynchronous and precompiled nature of computation on the WSE requires a custom solution. Cerebras will attempt to bridge compatibility with them in the future.