Train with gradient accumulation#
Note
Gradient accumulation is only available for transformer-type models.
Gradient accumulation is a technique that allows training with larger effective batch sizes than can physically fit in the available device memory. As illustrated in Fig. 11, a batch size exceeding the device memory capacity can be divided into smaller micro-batches. Each micro-batch is computed separately, and the resulting gradients are accumulated across micro-batches before the final update to the network weights occurs. This way, gradient accumulation emulates a bigger batch size by running multiple smaller micro-batches and combining the results.
If gradient accumulation is enabled, the compiler will drop the model to a smaller micro-batch size if the original batch size per CS-2 system does not fit into device memory or the compiler estimates that a lower micro-batch will achieve significantly better samples/second performance. If the micro_batch_size parameter is set in the yaml config (see further below), gradient accumulation will use that micro-batch size directly.
Warning
In release 2.0.0 enabling gradient accumulation without setting an explicit micro-batch size will direct the stack to search for a performant micro-batch size. This can lead to large increases in model compile time.
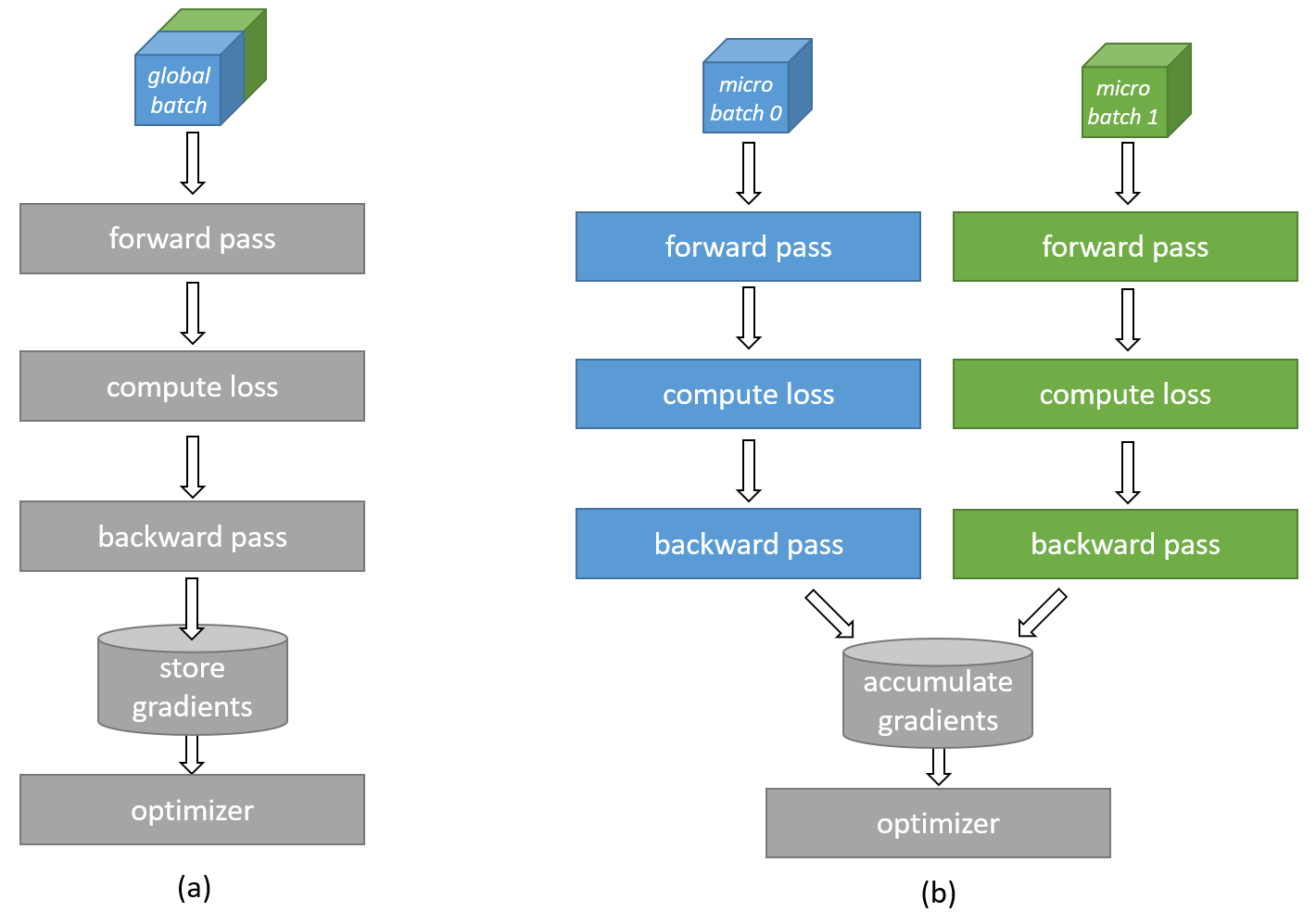
Fig. 11 Gradient accumulation computation#
How to enable#
To enable gradient accumulation, set use_cs_grad_accum: True in the runconfig section of the model params yaml file.
Unless micro_batch_size is set in the yaml file, the software stack will automatically choose an appropriate micro-batch size. It is preferred that micro_batch_size is set to significantly reduce compile times and potentially improve performance.
Note
Gradient accumulation will auto-disable for models that it does not support. This includes models using batch normalization, or other kinds of non-linear computation over the batch dimension.
Micro-batch size setting in YAML params#
To set the micro-batch size for gradient accumulation, set the micro-batch size for gradient accumulation in the train_input or eval_input section of the YAML file by providing a suitable value to the micro_batch_size parameter.
When setting the value of this parameter, ensure that num_csx and batch_size are consistent with the supplied value. Specifically, batch_size/num_csx should be a multiple of micro_batch_size. A RuntimeError will be raised if this condition is not met. By default, micro_batch_size is set to None, and the compiler will try to choose the best micro_batch_size.
A list of micro-batch sizes known to have good performance is suggested below. Though GPT-3 models are specified, these micro-batch sizes should be a good estimate for other GPT style models (BLOOM, LLaMA, etc) of similar sizes.
Model Family |
Model Size (Params) |
Micro Batch Size (MBS) |
|---|---|---|
GPT-3 |
1.3B |
253 |
GPT-3 |
2.7B |
198 |
GPT-3 |
6.7B |
121 |
GPT-3 |
13B |
99 |
GPT-3 |
20B |
77 |
GPT-3 |
30B |
69 |
GPT-3 |
39B |
55 |
GPT-3 |
65B |
55 |
GPT-3 |
82B |
48 |
GPT-3 |
175B |
35 |
T5 |
3B |
256 |
T5 |
11B |
520 |
Note
The batch size set on the yaml configuration is the global batch size. This means the batch size per CS-2 system is computed as the global batch size divided by the number of CS-2s used.
Known issues and limitations#
The current known limitations include:
Vision models (CNNs) are not fully tested.
Batch normalization is not supported.
Support is limited to networks whose gradients and statistics can be accumulated across sub-batches.
It’s recommended that the
micro_batch_sizeparameter be set to avoid long compile times.