Multi-model Inference
On This Page
Multi-model Inference¶
You can run multiple models on the CS system, send inference requests to these models and receive prediction responses. These multiple models can be either the copies of the same model, or each a different model, or a combination of the two. See the following diagram:
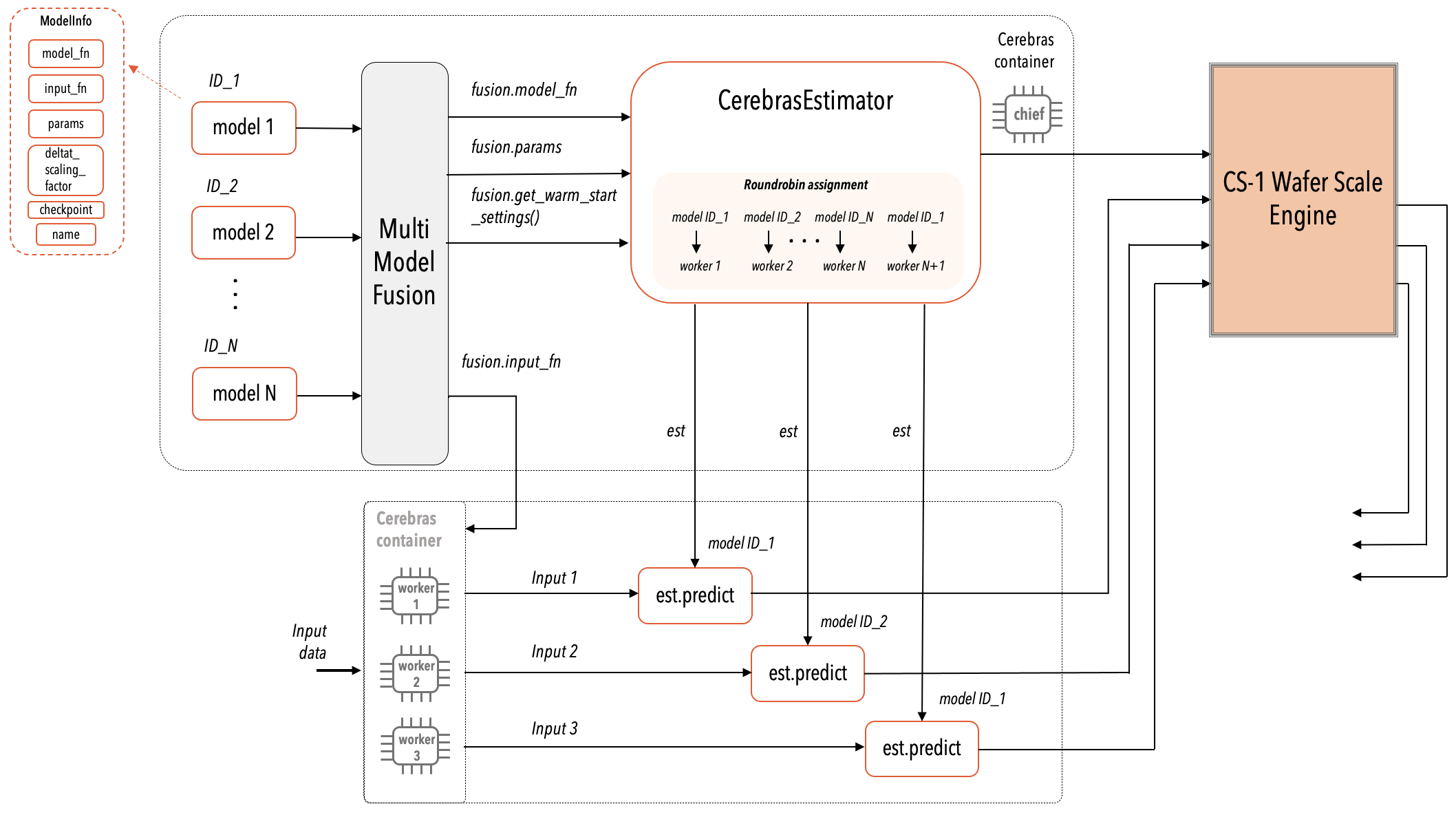
Fig. 4 A High-level View of Multi-model Inference¶
Important
The multi-model execution on the CS system is supported only for the inference.
Running multi-model inference¶
Before proceeding further, refer to Train, Eval and Predict on how to run the standard single-model inference on the CS system.
Running a multi-model inference works like this:
Two functions,
ModelInfoandMultiModelFusionare provided to handle the multi-model inference.You use these two functions in your multi-model Python run script, for example,
run_mm.py, as described in this section. See Example run_mm.py.Finally, run the
run_mm.pyscript in the inference mode as follows:python run_mm.py --mode predict \ --params configs/your-params-file.yaml \ --cs_ip 10.255.253.0
ModelInfo¶
In your run_mm.py script, use the ModelInfo class to create instances of each individual model. Refer to the figure A High-level View of Multi-model Inference. The fields of the ModelInfo class are as follows:
ModelInfo(
model_fn=model_fn,
input_fn=rebatch_input_fn(input_fn),
params=params,
deltat_scaling_factor=deltat_scale_factor,
name="model_" + scenario
)
Refer to the run_mm.py script for full details.
MultiModelFusion¶
Refer to the figure A High-level View of Multi-model Inference. The MultiModelFusion function accepts as input any number of models in the form of ModelInfo objects and fuses them together into a single TensorFlow model. This fused TensorFlow model is then passed to CerebrasEstimator for the normal compilation to occur.
Each ModelInfo model object has a unique model ID. The input data streamers then route specific inference requests only to the targeted model ID. The CerebrasEstimator automatically assigns each worker to one model ID in a round-robin fashion. For example, if a compile contains 2 disjoint models and 3 workers, worker 1 is assigned to model 1, worker 2 is assigned to model 2, and worker 3 is assigned to model 1 and so on.
Each worker uses the fused input function to generate the data for all the models, but only streams data for the model that it is assigned to. This happens automatically within the CerebrasEstimator.
Example run_mm.py¶
See the following Tensorflow example for a multi-model inference:
"""
Script to run multi model
"""
import argparse
import os
import sys
import numpy as np
import tensorflow as tf
from cerebras.models.common.estimator.tf.cs_estimator import CerebrasEstimator
from cerebras.models.common.estimator.tf.run_config import CSRunConfig
from cerebras.models.common.run_utils import (
check_env,
get_csrunconfig_dict,
is_cs,
save_params,
update_params_from_args,
)
from models.data import input_fn
from models.model import model_fn
from models.utils import get_params
from cerebras.tf.model_fusion import MultiModelFusion
from cerebras.tf.model_fusion import ModelInfo
def rebatch_input_fn(input_fn, batch_size=1):
"""
Returns a modified input_fn with the batch size set to `batch_size`.
:param input_fn: The original input_fn.
:param batch_size: Batch size to set for the new input_fn. Defaults to 1.
:returns: A modified input_fn whose batch size is `batch_size`.
"""
def _rebatched_input_fn(params):
ds = input_fn(params)
ds = ds.unbatch()
ds = ds.batch(batch_size, drop_remainder=True)
return ds
return _rebatched_input_fn
def build_model_instance(params_path, deltat_scale_factor: float, scenario: str = "base"):
"""
Returns a model info.
:param mode: One of estimator mode keys to build the model with.
:param scenario: Model scenario to build.
:param deltat_scale_factor: DeltaT scaling factor to use.
:returns: A model info object.
"""
params = get_params(params_path, config=scenario)
params["model"]["n_towers"] = 2
params["model"]["in_parallel"] = True
params["runconfig"]["mode"] = "infer"
return ModelInfo(
model_fn=model_fn,
input_fn=rebatch_input_fn(input_fn),
params=params,
deltat_scaling_factor=deltat_scale_factor,
name="model_" + scenario
)
def create_arg_parser():
parser = argparse.ArgumentParser(
description="run model in either train, eval, compile_only, or \
validate_only mode. example: python run.py -p params.yaml \
-m train"
)
parser.add_argument(
"--cs_ip", help="CS system IP address, defaults to None", default=None
)
parser.add_argument(
"-p",
"--params",
help="path to params yaml file",
required=False,
default="./params.yaml",
)
parser.add_argument(
"-m",
"--mode",
choices=[
"validate_only",
"compile_only",
"train",
"eval",
"infer",
"infer_cpp",
],
help=(
"Can choose from validate_only, compile_only, train, infer "
+ "or eval. Defaults to validate_only."
+ " Validate only will only go up to kernel matching."
+ " Compile only continues through and generate compiled"
+ " executables."
+ " Train will compile and train if on CS system,"
+ " and just train locally (CPU/GPU) if not on CS system."
+ " Eval will run eval locally."
" Predict will generate predictions and will skip loss calculation.\
The number of generated inferences is given by \
params['inference']['infer_params']['max_steps']"
),
)
parser.add_argument(
"-o",
"--model_dir",
type=str,
help="Save compilation and non-simfab outputs",
default="./model_dir",
)
parser.add_argument(
"--variants",
nargs="*",
help="List of <variant,count> models to instantiate.",
default=["base,1", "encoder_deep,1", "djinn_wide,1", "decoder_shallow,1"]
)
return parser
def main():
# SET UP
parser = create_arg_parser()
args = parser.parse_args(sys.argv[1:])
params_path = args.params
params = get_params(params_path)
models = []
for variant_spec in args.variants:
scenario, count = variant_spec.split(",")
params = get_params(args.params, config=scenario)
models.extend([
build_model_instance(
params_path,
deltat_scale_factor=1,
scenario=scenario,
)
for _ in range(int(count))
])
fusion = MultiModelFusion(models)
runconfig_params = params["runconfig"]
update_params_from_args(args, runconfig_params)
# save params for reproducibility
save_params(params, model_dir=runconfig_params["model_dir"])
# get runtime configurations
use_cs = is_cs(runconfig_params)
csrunconfig_dict = get_csrunconfig_dict(runconfig_params)
check_env(runconfig_params)
if params["runconfig"]["mode"] == "infer_cpp":
# This import will result in global imports of modules that are built
# and thus not accessible on a gpu run (will result in import error).
# So moving the import to the context it is needed.
from cerebras.tf.utils import prep_orchestrator
prep_orchestrator()
stack_params = {
"multi_model_info": fusion.stack_params,
}
est_config = CSRunConfig(
stack_params=stack_params, cs_ip=runconfig_params["cs_ip"], **csrunconfig_dict,
)
est = CerebrasEstimator(
model_fn=fusion.model_fn,
model_dir=runconfig_params["model_dir"],
config=est_config,
params=fusion.params,
)
output = None
if params["runconfig"]["mode"] == tf.estimator.ModeKeys.TRAIN:
est.train(
input_fn=input_fn,
max_steps=runconfig_params["max_steps"],
use_cs=use_cs,
)
elif params["runconfig"]["mode"] == tf.estimator.ModeKeys.EVAL:
output = est.evaluate(
input_fn=input_fn, steps=runconfig_params["eval_steps"],
)
elif params["runconfig"]["mode"] == tf.estimator.ModeKeys.PREDICT:
pred_dir = os.path.join(runconfig_params["model_dir"], "predictions")
os.makedirs(pred_dir, exist_ok=True)
sys_name = "cs" if use_cs else "tf"
file_to_save = f"predictions_{sys_name}_{est_config.task_id}.npz"
output = []
num_samples = runconfig_params["infer_steps"]
preds = est.predict(
input_fn=fusion.input_fn, num_samples=num_samples, use_cs=use_cs
)
for pred in preds:
output.append(pred)
if len(output) > 0:
np.savez(os.path.join(pred_dir, file_to_save), output)
elif params["runconfig"]["mode"] == "infer_cpp":
preds = est.predict(
input_fn=fusion.input_fn, num_samples=1, use_cs=True
)
else:
est.compile(
fusion.input_fn,
validate_only=(params["runconfig"]["mode"] == "validate_only"),
)
return output
if __name__ == "__main__":
tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.INFO)
output = main()