Training and fine-tuning a Large Language Model (LLM)#
Estimated time: 30 mins to 1 hour
Overview#
This tutorial teaches you how to use the Cerebras Wafer-Scale cluster to train, fine-tune, and evaluate a Large Language Model (LLM) and visualize the results using TensorBoard. The model you will use is the GPT-3 111M with the WikiText-2 dataset. You need access to Cerebras’s Wafer-Scale cluster to train the model and fine-tune it from an existing checkpoint. Later, you will evaluate the models and visualize the results using TensorBoard. Finally, you will learn how to port the models to Hugging Face to generate outputs.
If you are interested in using a different dataset, you can still use the create HDF5 dataset tool from Cerebras Model Zoo used in step 2. In addition, if you are using a larger GPT model, change the YAML configuration used in steps 4 and 5. Here are some examples of GPT3 model configurations from Cerebras Model Zoo GPT and other GPT-3 configurations.
Prerequisites#
You have access to the user node in the Cerebras Wafer-Scale cluster. Contact your sys admin if you face any issues in the system configuration.
Setting up the Cerebras Model Zoo#
For convenience, you will set up the data and code inside a parent folder called demo - a directory that you will have to create yourself. In addition, you will define an environment variable called PARENT_CS to return to this parent directory at the anytime.
1. Create a parent directory, demo, to include all the data, code, and checkpoints. Export an environment variable PARENT_CS with the full path to the parent directory. This environment variable will be helpful when pointing to the absolute path during the execution.
mkdir demo
cd demo
export PARENT_CS=$(pwd)
2. Clone the Cerebras Model Zoo inside the demo folder, a repository with reference models and tools to run on the Cerebras Wafer-Scale cluster.
git clone https://github.com/Cerebras/modelzoo.git
Output
Cloning into 'modelzoo'...
remote: Enumerating objects: 1690, done.
remote: Counting objects: 100% (163/163), done.
remote: Compressing objects: 100% (79/79), done.
remote: Total 1690 (delta 105), reused 85 (delta 84), pack-reused 1527
Receiving objects: 100% (1690/1690), 21.58 MiB | 27.35 MiB/s, done.
Resolving deltas: 100% (942/942), done.
At this point, you should have a folder called modelzoo inside the demo parent directory.
Preparing data for the Cerebras Wafer-Scale cluster#
Note
Cerebras Model Zoo contains customized scripts to download and prepare OWT and Pile datasets. If interested, refer to them when training GPT-style models with OWT or Pile datasets.
Hierarchical Data Format, Version 5(HDF5) files provide an efficient way of loading data in the Cerebras’s Wafer-Scale cluster. The Cerebras Model Zoo contains a create_hdf5_dataset.py script that tokenizes the input documents and creates token IDs, labels, and attention masks. For more information, refer to hdf5_dataset_gpt.
1. Download the WikiText-2 raw dataset by first creating a data folder, and in the folder, download the dataset’s zip file containing the dataset.
cd $PARENT_CS
mkdir data
cd data
wget https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-2-raw-v1.zip
Output
--2023-04-25 00:00:00-- https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-2-raw-v1.zip
Resolving s3.amazonaws.com (s3.amazonaws.com)... 52.216.137.70, 52.217.89.246, 52.217.121.224, ...
Connecting to s3.amazonaws.com (s3.amazonaws.com)|52.216.137.70|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 4721645 (4.5M) [application/zip]
Saving to: ‘wikitext-2-raw-v1.zip’
100%[===============================================================>] 4,721,645 917KB/s in 6.3s
2023-04-25 00:00:00 (738 KB/s) - ‘wikitext-2-raw-v1.zip’ saved [4721645/4721645]
Decompress the zip file.
unzip wikitext-2-raw-v1.zip
Output
Archive: wikitext-2-raw-v1.zip
creating: wikitext-2-raw/
inflating: wikitext-2-raw/wiki.test.raw
inflating: wikitext-2-raw/wiki.valid.raw
inflating: wikitext-2-raw/wiki.train.raw
Remove the zip file.
rm wikitext-2-raw-v1.zip
2. Inside the wikitext-2-raw-v1 folder, you will find three files corresponding to train, validation, and test splits. Explore these files to understand the raw dataset format. The data is in txt format.
head -n5 wikitext-2-raw/wiki.train.raw
Output
= Valkyria Chronicles III =
Senjō no Valkyria 3 : Unrecorded Chronicles ( Japanese : 戦場のヴァルキュリア3 , lit . Valkyria of the Battlefield 3 ) , commonly referred to as Valkyria Chronicles III outside Japan , is a tactical role @-@ playing video game developed by Sega and Media.Vision for the PlayStation Portable . Released in January 2011 in Japan , it is the third game in the Valkyria series . Employing the same fusion of tactical and real @-@ time gameplay as its predecessors , the story runs parallel to the first game and follows the " Nameless " , a penal military unit serving the nation of Gallia during the Second Europan War who perform secret black operations and are pitted against the Imperial unit " Calamaty Raven " .
The game began development in 2010 , carrying over a large portion of the work done on Valkyria Chronicles II . While it retained the standard features of the series , it also underwent multiple adjustments , such as making the game more forgiving for series newcomers . Character designer Raita Honjou and composer Hitoshi Sakimoto both returned from previous entries , along with Valkyria Chronicles II director Takeshi Ozawa . A large team of writers handled the script . The game 's opening theme was sung by May 'n .
The create_hdf5_dataset.py script expects all the files in the same folder to belong to the same split. Therefore, create three folders - train, test, and valid, and move the corresponding files to each folder. In addition, add a .txt file extension to each file since each file is in a raw format.
mkdir wikitext-2-raw/train
mv wikitext-2-raw/wiki.train.raw wikitext-2-raw/train/wiki.txt
mkdir wikitext-2-raw/test
mv wikitext-2-raw/wiki.test.raw wikitext-2-raw/test/wiki.txt
mkdir wikitext-2-raw/valid
mv wikitext-2-raw/wiki.valid.raw wikitext-2-raw/valid/wiki.txt
The create_hdf5_dataset.py script also parses file types .json, .jsonl.zst, and .jsonl.zst.tar. For more information on the input format, refer to hdf5_dataset_gpt
Preparing the data in HDF5 format#
1. Before you prepare the data in an HDF5 format, set up a Python virtual environment with all the dependencies needed for preprocessing. Create this virtual environment in the parent directory demo. For more informaion on HDF5 format, click here.
cd $PARENT_CS
/opt/python3.8/bin/python3.8 -m venv venv_cerebras_pt
source venv_cerebras_pt/bin/activate
Note that now you should be in the (venv_cerebras_pt) environment.
pip install --upgrade pip
Output
Collecting ...
Downloading ...
Installing collected packages: ...
Install Model Zoo dependencies. (See Clone Cerebras Model Zoo)
pip install -r modelzoo/requirements.txt --extra-index-url https://download.pytorch.org/whl/cpu
Output
Collecting ...
Downloading ...
Installing collected packages: ...
2. Now that your venv_cerebras_pt virtual environment has been set up and activated, launch the create_hdf5_dataset.py script. This script resides in the modelzoo folder in the Cerebras Model Zoo repository. Launch this script for every data split you intend to use. In this case, you will preprocess the train and valid splits and save the preprocessed data in an HDF5 format in the data/wikitext-2-hdf5/ folder.
Prepare the data for the train set:
mkdir data/wikitext-2-hdf5/
python modelzoo/data_preparation/nlp/hdf5_preprocessing/create_hdf5_dataset.py\
LMData \
--params ./configs/autoregressive_lm_preprocessing.yaml
--input_dir data/wikitext-2-raw/train/ \
--output_dir data/wikitext-2-hdf5/train/ \
--files_per_record 100 \
Output
INFO:modelzoo/data_preparation/nlp/hdf5_preprocessing/create_hdf5_dataset.py:
Writing data to data/wikitext-2-hdf5/train/.
INFO:utils:User arguments can be found at data/wikitext-2-hdf5/train/data_params.json.
Parsed 1 input files. Files written : : 12it [00:15, 1.27s/it]
INFO:modelzoo/data_preparation/nlp/hdf5_preprocessing/create_hdf5_dataset.py:
Finished writing data to data/wikitext-2-hdf5/train/. Runtime arguments and outputs can be found at data/wikitext-2-hdf5/train/data_params.json.
INFO:modelzoo/data_preparation/nlp/hdf5_preprocessing/create_hdf5_dataset.py:Verifying the converted dataset at: data/wikitext-2-hdf5/train/
INFO:modelzoo/data_preparation/nlp/hdf5_preprocessing/create_hdf5_dataset.py:Done verifying the converted dataset.
The create_hdf5_dataset.py is instrumented with multiple flags. Our version of the Python script uses the following flags:
Flag |
Description |
|---|---|
|
For processing language modelling datasets that are in |
|
Path to YAML config file for setting dataset preprocessing parameters. Optional alternative for providing command line arguments. |
|
Folder where all the |
|
Destination folder |
|
Files per record is set to 100 in comparison to the default setting, which is 50,000. Given that there are 1180 training samples, the number of files per record should be smaller than the total number of samples. After preprocessing, the total number of samples will be |
After running the Python script, you should have an output directory: data/wikitext-2-hdf5/train/. The following list shows the content of the output directory:
ls data/wikitext-2-hdf5/train/
Output
├── checkpoint_0.txt
├── data_params.json
├── examples_0_0.h5
├── examples_1_0.h5
├── examples_2_0.h5
├── examples_3_0.h5
├── examples_4_0.h5
├── examples_5_0.h5
├── examples_6_0.h5
├── examples_7_0.h5
├── examples_8_0.h5
├── examples_9_0.h5
├── examples_10_0.h5
├── examples_11_0.h5
3. Prepare the data in the validation set by changing the --input_dir to data/wikitext-2-raw/valid/ and --output_dir to data/wikitext-2-hdf5/valid/:
python modelzoo/data_preparation/nlp/hdf5_preprocessing/create_hdf5_dataset.py \
LMData \
--params ./configs/autoregressive_lm_preprocessing.yaml
--input_dir data/wikitext-2-raw/valid/ \
--output_dir data/wikitext-2-hdf5/valid/ \
--files_per_record 100 \
You should have an output directory: data/wikitext-2-hdf5/valid/. The following list shows the content of the output directory:
ls data/wikitext-2-hdf5/valid/
Output
├── checkpoint_0.txt
├── data_params.json
├── examples_0_0.h5
├── examples_1_0.h5
Note
The create_hdf5_dataset.py script only tokenizes your dataset. Perform data cleaning and shuffling before preparing the data in the HDF5 format, as it depends on the quality of your dataset. Additional resources available in Cerebras Model Zoo can be found in Data processing and dataloaders.
Training GPT-3 111M model from scratch#
1. Create a copy of the Cerebras-GPT 111M yaml configuration file to point to the WikiText-2 dataset preprocessed in step 2. Make sure that the venv_cerebras_pt is active.
cd $PARENT_CS
cp /models/nlp/gpt3/configs/mz/Cerebras_GPT/111m.yaml custom_config_GPT111M.yaml
2. Set the absolute path directory for data/wikitext-2-hdf5/train. You can obtain the absolute path using realpath, or appending data/wikitext-2-hdf5/train/ to the absolute path in $PARENT_CS.
cd $PARENT_CS
realpath data/wikitext-2-hdf5/train/
<absolute_path>/demo/data/wikitext-2-hdf5/train/
3. With the absolute path set, modify the custom_config_GPT111M.yaml file.
vi custom_config_GPT111M.yaml
4. Modify the data_dir flag for training and evaluation inputs:
train_input:
data_processor: "GptHDF5DataProcessor"
data_dir: "<absolute_path>/demo/data/wikitext-2-hdf5/train/"
max_sequence_length: 2048
...
eval_input:
data_processor: "GptHDF5DataProcessor"
data_dir: "<absolute_path>/demo/data/wikitext-2-hdf5/valid/"
...
5. To shorten the runtime, modify the number of max_steps for training, the eval_steps for evaluation, and the checkpoint frequency.
runconfig:
max_steps: 10
eval_steps: 1
checkpoint_steps: 10
With the new YAML configuration, you are ready to launch the training job.
Alternately, you can use screen, a terminal multiplex, so that your training does not stop if you lose access to the terminal. For this, start a new screen session called train_wsc.
screen -S train_wsc
6. Inside this screen session, if not already active, activate the Cerebras virtual environment venv_cerebras_pt.
cd $PARENT_CS
source venv_cerebras_pt/bin/activate
7. Run the run.py script file associated with the GPT-3 models in Cerebras Model Zoo.
Each model in Cerebras Model Zoo contains a run.py script instrumented to easily launch training and evaluation in the Cerebras Wafer-Scale cluster and other AI accelerators. To learn more on how to launch a training, visit Launch your job, and to view the run.py code for the GPT-3 model, visit here.
python models/nlp/gpt3/run.py \
CSX \
--params custom_config_GPT111M.yaml \
--num_csx=1 \
--model_dir train_from_scratch_GPT111M \
--mode train \
--mount_dirs $PARENT_CS $PARENT_CS/modelzoo \
--python_paths $PARENT_CS/modelzoo \
--job_labels model=GPT111M
The following list describes the flags and their description:
Flag |
Description |
|---|---|
|
Points to the YAML configuration file you customed with the training data paths |
|
Number of |
|
New directory containing all the checkpoints and logging information |
|
Specifies that you are training the model as opposed to evaluation |
|
Mounts directories to the Cerebras Wafer-Scale cluster. In this case, all the data and code is in the parent directory |
|
Enables adding the Cerebras Model Zoo to the list of paths to be exported to |
|
A list of equal-sign-separated key value pairs served as job label, to query using csctl. |
Note
Once you have submitted your job to execute in the Cerebras Wafer-Scale cluster, you can track the progress or kill your job using the csctl tool. You can also monitor the performance using a Grafana dashboard
8. Detach the screen using CTRL+A D and reattach the screen using screen -r train_wsc.
Once the training job is complete, you will find inside the train_from_scratch_GPT111M folder:
ls train_from_scratch_GPT111M
Output
├── cerebras_logs
└── latest
├── latest_compile
├── performance
└── run.log
├── checkpoint_10.mdl
└── train
├── events.out.tfevents.########.#####
└── params_train.yaml
where latest_compile and cerebras_logs contain Cerebras-specific information collected while compiling and executing the model, checkpoint_10.mdl is the checkpoint saved after ten steps, train contains the metrics logged during execution, and the YAML configuration file, and run_<data>_######.log contains the command line output during execution.
cat train_from_scratch_GPT111M/run_<date>_######.log
Output
2023-04-25 16:47:58,410 INFO: No checkpoint was provided, model parameters will be initialized randomly
2023-04-25 16:48:06,871 INFO: Compiling the model. This may take a few minutes.
2023-04-25 16:48:29,129 INFO: ClusterClient: server=10.253.20.16:443, authority=cluster-server.mb-systemf159.cerebras.com, cert=/opt/cerebras/certs/tls.crt
2023-04-25 16:48:29,205 INFO: Initiating a new compile wsjob against the cluster server.
2023-04-25 16:48:29,224 INFO: compile job id: wsjob-bkto6uyvdwfmkwufj37jwk, log path: /cb/tests/cluster-mgmt/mb-systemf159/workdir/wsjob-bkto6uyvdwfmkwufj37jwk
2023-04-25 16:48:39,236 INFO: Poll ingress status: Waiting for coordinator to be ready.
2023-04-25 16:48:49,245 INFO: Poll ingress status: Coordinator svc ready, poll ingress success.
2023-04-25 16:48:49,245 INFO: Ingress is ready.
2023-04-25 16:48:49,245 INFO: Cluster mgmt job handle: {'job_id': 'wsjob-bkto6uyvdwfmkwufj37jwk', 'service_url': '10.253.20.16:443', 'service_authority': 'wsjob-bkto6uyvdwfmkwufj37jwk-coordinator-0.cluster-server.mb-systemf159.cerebras.com', 'credentials_path': '/opt/cerebras/certs/tls.crt'}
2023-04-25 16:48:49,249 INFO: Creating a framework GRPC client: 10.253.20.16:443, <grpc.ChannelCredentials object at 0x7ffec44a4950>, wsjob-bkto6uyvdwfmkwufj37jwk-coordinator-0.cluster-server.mb-systemf159.cerebras.com
2023-04-25 16:54:14,027 INFO: Compile successfully written to cache directory: cs_8947482215861706321
2023-04-25 16:54:14,052 INFO: Compile for training completed successfully!
2023-04-25 16:54:14,052 INFO: ClusterClient: server=10.253.20.16:443, authority=cluster-server.mb-systemf159.cerebras.com, cert=/opt/cerebras/certs/tls.crt
2023-04-25 16:54:14,053 INFO: Initiating a new execute wsjob against the cluster server.
2023-04-25 16:54:14,081 INFO: execute job id: wsjob-c6twhzts4dky97yy8wsdyr, log path: /cb/tests/cluster-mgmt/mb-systemf159/workdir/wsjob-c6twhzts4dky97yy8wsdyr
2023-04-25 16:54:24,090 INFO: Poll ingress status: Waiting for job running, current status: LockGranted, msg: lock grant success
2023-04-25 16:54:34,100 INFO: Poll ingress status: Waiting for coordinator to be ready.
2023-04-25 16:55:04,132 INFO: Poll ingress status: Coordinator svc ready, poll ingress success.
2023-04-25 16:55:04,133 INFO: Ingress is ready.
2023-04-25 16:55:04,133 INFO: Cluster mgmt job handle: {'job_id': 'wsjob-c6twhzts4dky97yy8wsdyr', 'service_url': '10.253.20.16:443', 'service_authority': 'wsjob-c6twhzts4dky97yy8wsdyr-coordinator-0.cluster-server.mb-systemf159.cerebras.com', 'credentials_path': '/opt/cerebras/certs/tls.crt'}
2023-04-25 16:55:04,133 INFO: Removing a framework GRPC client: 10.253.20.16:443
2023-04-25 16:55:04,133 INFO: Creating a framework GRPC client: 10.253.20.16:443, <grpc.ChannelCredentials object at 0x7ffec445d9d0>, wsjob-c6twhzts4dky97yy8wsdyr-coordinator-0.cluster-server.mb-systemf159.cerebras.com
2023-04-25 16:55:05,306 INFO: Preparing to execute using 1 CSX
2023-04-25 16:55:05,326 INFO: Monitoring Coordinator for Runtime server errors
2023-04-25 16:55:22,813 INFO: About to send initial weights
2023-04-25 16:55:41,352 INFO: Finished sending initial weights
2023-04-25 16:59:51,055 INFO: | Train Device=CSX, Step=1, Loss=10.93750, Rate=211.62 samples/sec, GlobalRate=211.61 samples/sec
2023-04-25 16:59:51,493 INFO: | Train Device=CSX, Step=2, Loss=10.93750, Rate=249.29 samples/sec, GlobalRate=238.95 samples/sec
2023-04-25 16:59:51,928 INFO: | Train Device=CSX, Step=3, Loss=10.93750, Rate=265.14 samples/sec, GlobalRate=250.07 samples/sec
2023-04-25 16:59:52,377 INFO: | Train Device=CSX, Step=4, Loss=10.87500, Rate=266.36 samples/sec, GlobalRate=254.13 samples/sec
2023-04-25 16:59:52,835 INFO: | Train Device=CSX, Step=5, Loss=10.87500, Rate=263.95 samples/sec, GlobalRate=255.73 samples/sec
2023-04-25 16:59:53,266 INFO: | Train Device=CSX, Step=6, Loss=10.81250, Rate=272.41 samples/sec, GlobalRate=259.20 samples/sec
2023-04-25 16:59:53,765 INFO: | Train Device=CSX, Step=7, Loss=10.75000, Rate=253.24 samples/sec, GlobalRate=256.35 samples/sec
2023-04-25 16:59:54,234 INFO: | Train Device=CSX, Step=8, Loss=10.68750, Rate=254.73 samples/sec, GlobalRate=256.27 samples/sec
2023-04-25 16:59:54,672 INFO: | Train Device=CSX, Step=9, Loss=10.68750, Rate=266.52 samples/sec, GlobalRate=258.16 samples/sec
2023-04-25 16:59:55,313 INFO: | Train Device=CSX, Step=10, Loss=10.62500, Rate=218.96 samples/sec, GlobalRate=248.74 samples/sec
2023-04-25 16:59:55,314 INFO: Saving checkpoint at global step 10
2023-04-25 17:00:31,361 INFO: Saved checkpoint at global step: 10
2023-04-25 17:00:31,361 INFO: Training completed successfully.
2023-04-25 17:00:31,361 INFO: Processed 1200 sample(s) in 40.873082399368286 seconds.
Fine-tuning using checkpoints from Cerebras-GPT model#
1. Download the Cerebras-GPT 111M checkpoint compatible with the Cerebras Wafer-Scale Cluster from Cerebras Model Zoo.
You can find all the Cerebras-GPT checkpoints in the Cerebras-GPT site in Cerebras Model Zoo.
cd $PARENT_CS
mkdir Cerebras-checkpoint
cd Cerebras-checkpoint
wget https://cerebras-public.s3.us-west-2.amazonaws.com/cerebras-gpt-checkpoints/dense/111M/sp/cerebras-gpt-dense-111m-sp-checkpoint_final.mdl
Output
--2023-04-25 17:07:58-- https://cerebras-public.s3.us-west-2.amazonaws.com/cerebras-gpt-checkpoints/dense/111M/sp/cerebras-gpt-dense-111m-sp-checkpoint_final.mdl
Resolving cerebras-public.s3.us-west-2.amazonaws.com (cerebras-public.s3.us-west-2.amazonaws.com)... 52.92.229.250, 52.92.181.130, 52.92.132.2, ...
Connecting to cerebras-public.s3.us-west-2.amazonaws.com (cerebras-public.s3.us-west-2.amazonaws.com)|52.92.229.250|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1337938518 (1.2G) [binary/octet-stream]
Saving to: ‘cerebras-gpt-dense-111m-sp-checkpoint_final.mdl’
100%[=============================================================================================================>] 1,337,938,518 25.1MB/s in 45s
2023-04-25 17:08:44 (28.3 MB/s) - ‘cerebras-gpt-dense-111m-sp-checkpoint_final.mdl’ saved [1337938518/1337938518]
Once you have the checkpoint, you are ready to launch the training job. For this, you can start a new screen session or reuse the screen session used during training from scratch. To reattached the train_wsc screen, use
screen -r train_wsc
2. Inside this screen session, if not already active, you will activate the Cerebras virtual environment venv_cerebras_pt.
cd $PARENT_CS
source venv_cerebras_pt/bin/activate
You will now run the same run.py script used during the training from scratch with new flags.
3. Change the following flags:
Flag |
Description |
|---|---|
|
Specifies a different model directory to save checkpoints and logging information |
|
Specifies the path where the Cerebras-GPT 111M model is. You will be using this checkpoint to initialize the model weights |
|
Flag used in conjunction with |
python models/nlp/gpt3/run.py \
CSX \
--params custom_config_GPT111M.yaml \
--num_csx=1 \
--model_dir finetune_GPT111M \
--mode train \
--mount_dirs $PARENT_CS $PARENT_CS/modelzoo \
--python_paths $PARENT_CS/modelzoo \
--checkpoint_path Cerebras-checkpoint/cerebras-gpt-dense-111m-sp-checkpoint_final.mdl \
--load_checkpoint_states="model" \
--job_labels model=finetune_GPT111M
Once the training job is over, you will find inside the finetune_GPT111M folder:
ls finetune_GPT111M
Output
├── cerebras_logs
└── latest
├── performance
└── run.log
├── checkpoint_10.mdl
└── train
├── events.out.tfevents.########.#####
└── params_train.yaml
The run_<data>_######.log contains the command line output generated during execution.
cat finetune_GPT111M/run_<date>_######.log
Output
2023-04-25 17:14:38,683 INFO: Loading weights from checkpoint Cerebras-checkpoint/cerebras-gpt-dense-111m-sp-checkpoint_final.mdl
2023-04-25 17:14:41,002 WARNING: Using an older checkpoint format 0.1 (current version: 0.2). Using it to load the state dict may cause unexpected behaviour.
2023-04-25 17:14:48,441 INFO: Compiling the model. This may take a few minutes.
2023-04-25 17:15:05,468 INFO: ClusterClient: server=10.253.20.16:443, authority=cluster-server.mb-systemf159.cerebras.com, cert=/opt/cerebras/certs/tls.crt
2023-04-25 17:15:05,483 INFO: Initiating a new compile wsjob against the cluster server.
2023-04-25 17:15:05,495 INFO: compile job id: wsjob-sf96htcijwqwcu2mqd9cyc, log path: /cb/tests/cluster-mgmt/mb-systemf159/workdir/wsjob-sf96htcijwqwcu2mqd9cyc
2023-04-25 17:15:15,504 INFO: Poll ingress status: Waiting for coordinator to be ready.
2023-04-25 17:15:25,510 INFO: Poll ingress status: Coordinator svc ready, poll ingress success.
2023-04-25 17:15:25,511 INFO: Ingress is ready.
2023-04-25 17:15:25,511 INFO: Cluster mgmt job handle: {'job_id': 'wsjob-sf96htcijwqwcu2mqd9cyc', 'service_url': '10.253.20.16:443', 'service_authority': 'wsjob-sf96htcijwqwcu2mqd9cyc-coordinator-0.cluster-server.mb-systemf159.cerebras.com', 'credentials_path': '/opt/cerebras/certs/tls.crt'}
2023-04-25 17:15:25,513 INFO: Creating a framework GRPC client: 10.253.20.16:443, <grpc.ChannelCredentials object at 0x7ffed1a4b410>, wsjob-sf96htcijwqwcu2mqd9cyc-coordinator-0.cluster-server.mb-systemf159.cerebras.com
2023-04-25 17:15:25,725 INFO: Compile successfully written to cache directory: cs_8947482215861706321
2023-04-25 17:15:25,741 INFO: Compile for training completed successfully!
2023-04-25 17:15:25,741 INFO: ClusterClient: server=10.253.20.16:443, authority=cluster-server.mb-systemf159.cerebras.com, cert=/opt/cerebras/certs/tls.crt
2023-04-25 17:15:25,742 INFO: Initiating a new execute wsjob against the cluster server.
2023-04-25 17:15:25,769 INFO: execute job id: wsjob-wnadhxzntbisyzal9fdjx7, log path: /cb/tests/cluster-mgmt/mb-systemf159/workdir/wsjob-wnadhxzntbisyzal9fdjx7
2023-04-25 17:15:35,780 INFO: Poll ingress status: Waiting for coordinator to be ready.
2023-04-25 17:16:15,818 INFO: Poll ingress status: Coordinator svc ready, poll ingress success.
2023-04-25 17:16:15,819 INFO: Ingress is ready.
2023-04-25 17:16:15,819 INFO: Cluster mgmt job handle: {'job_id': 'wsjob-wnadhxzntbisyzal9fdjx7', 'service_url': '10.253.20.16:443', 'service_authority': 'wsjob-wnadhxzntbisyzal9fdjx7-coordinator-0.cluster-server.mb-systemf159.cerebras.com', 'credentials_path': '/opt/cerebras/certs/tls.crt'}
2023-04-25 17:16:15,819 INFO: Removing a framework GRPC client: 10.253.20.16:443
2023-04-25 17:16:15,819 INFO: Creating a framework GRPC client: 10.253.20.16:443, <grpc.ChannelCredentials object at 0x7ffed1a29cd0>, wsjob-wnadhxzntbisyzal9fdjx7-coordinator-0.cluster-server.mb-systemf159.cerebras.com
2023-04-25 17:16:15,839 INFO: Preparing to execute using 1 CSX
2023-04-25 17:16:15,853 INFO: Monitoring Coordinator for Runtime server errors
2023-04-25 17:16:31,447 INFO: About to send initial weights
2023-04-25 17:16:49,469 INFO: Finished sending initial weights
2023-04-25 17:21:01,176 INFO: | Train Device=CSX, Step=1, Loss=3.84375, Rate=206.34 samples/sec, GlobalRate=206.34 samples/sec
2023-04-25 17:21:01,621 INFO: | Train Device=CSX, Step=2, Loss=3.82812, Rate=244.47 samples/sec, GlobalRate=233.88 samples/sec
2023-04-25 17:21:02,049 INFO: | Train Device=CSX, Step=3, Loss=3.82812, Rate=266.12 samples/sec, GlobalRate=247.61 samples/sec
2023-04-25 17:21:02,502 INFO: | Train Device=CSX, Step=4, Loss=3.78125, Rate=265.31 samples/sec, GlobalRate=251.69 samples/sec
2023-04-25 17:21:02,935 INFO: | Train Device=CSX, Step=5, Loss=3.82812, Rate=272.36 samples/sec, GlobalRate=256.38 samples/sec
2023-04-25 17:21:03,393 INFO: | Train Device=CSX, Step=6, Loss=3.78125, Rate=266.22 samples/sec, GlobalRate=257.32 samples/sec
2023-04-25 17:21:03,838 INFO: | Train Device=CSX, Step=7, Loss=3.81250, Rate=268.26 samples/sec, GlobalRate=259.01 samples/sec
2023-04-25 17:21:04,276 INFO: | Train Device=CSX, Step=8, Loss=3.79688, Rate=271.54 samples/sec, GlobalRate=260.76 samples/sec
2023-04-25 17:21:04,740 INFO: | Train Device=CSX, Step=9, Loss=3.75000, Rate=263.77 samples/sec, GlobalRate=260.52 samples/sec
2023-04-25 17:21:05,339 INFO: | Train Device=CSX, Step=10, Loss=3.76562, Rate=225.80 samples/sec, GlobalRate=252.94 samples/sec
2023-04-25 17:21:05,341 INFO: Saving checkpoint at global step 10
2023-04-25 17:21:37,871 INFO: Saving step 10 in dataloader checkpoint
2023-04-25 17:21:38,542 INFO: Saved checkpoint at global step: 10
2023-04-25 17:21:38,543 INFO: Training completed successfully.
2023-04-25 17:21:38,543 INFO: Processed 1200 sample(s) in 37.947919607162476 seconds.
Evaluating the trained models and visualize using TensorBoard#
For all models, you can use the run.py script found in the Cerebras Model Zoo for evaluation purposes (i.e., only forward pass). GPT style models use the data specified in eval_input.data_dir, which you had set up in step 2. The run.py script provides three types of evaluation with the --mode flag:
Flag |
Description |
|---|---|
|
Evaluates a specific checkpoint. The latest checkpoint will be used if you don’t provide the |
|
Evaluates all the checkpoints inside a model directory once the model has been trained |
|
Evaluates the model periodically during the training process. |
|
Evaluates a model at a fixed frequency during training. This is convenient for identifying issues early in long training runs |
Note
The train and eval modes require different fabric programming in the CS-X system. Therefore, using train_and_eval mode in the Cerebras Wafer-Scale cluster results in additional overheads any time training is stopped to perform evaluation. When possible, we recommend using the eval_all mode instead.
Given that you have already trained the model in this demo, you will use the eval_all mode. To learn more about the different types of evaluation, visit Evaluate your model during training.
Note
When evaluating a model with run.py, the latest saved checkpoint will be used by default. If no checkpoint exists, then weights
will be initialized as stated in the YAML file, and the model will be evaluated using these weights.
If you want to evaluate a previously trained model, make sure that the checkpoints are available in the model_dir or provide
the --checkpoint_path flag.
1. To launch evaluation, reattach the train_wsc screen.
screen -r train_wsc
2. Inside this screen session, if not already active, activate the Cerebras virtual environment venv_cerebras_pt.
cd $PARENT_CS
source venv_cerebras_pt/bin/activate
Evaluating the model trained from scratch#
To evaluate the model trained from scratch, run the run.py script associated with the GPT-3 models in the Cerebras Model Zoo. This is the same run.py script used during training from scratch, but you will change the following flag:
|
Specifies the evaluation mode |
python models/nlp/gpt3/run.py \
CSX \
--params custom_config_GPT111M.yaml \
--num_csx=1 \
--model_dir train_from_scratch_GPT111M \
--mode eval_all \
--mount_dirs $PARENT_CS $PARENT_CS/modelzoo \
--python_paths $PARENT_CS/modelzoo
--job_labels model=eval_GPT111M
After the validation job is complete, you will find additional files inside the train_from_scratch_GPT111M folder, including an eval folder that contains the metrics logged during the model evaluation and a new run_<data>_######.log with the command line output during model evaluation. Here is an example of the command line output.
2023-04-25 19:53:51,947 INFO: Loading weights from checkpoint train_from_scratch_GPT111M/checkpoint_10.mdl
2023-04-25 19:53:54,879 INFO: Compiling the model. This may take a few minutes.
2023-04-25 19:53:56,869 INFO: ClusterClient: server=10.253.20.16:443, authority=cluster-server.mb-systemf159.cerebras.com, cert=/opt/cerebras/certs/tls.crt
2023-04-25 19:53:56,883 INFO: Initiating a new compile wsjob against the cluster server.
2023-04-25 19:53:56,895 INFO: compile job id: wsjob-kzid8uvxjgp7i3yvarv34i, log path: /cb/tests/cluster-mgmt/mb-systemf159/workdir/wsjob-kzid8uvxjgp7i3yvarv34i
2023-04-25 19:54:06,907 INFO: Poll ingress status: Waiting for coordinator to be ready.
2023-04-25 19:54:16,917 INFO: Poll ingress status: Coordinator svc ready, poll ingress success.
2023-04-25 19:54:16,917 INFO: Ingress is ready.
2023-04-25 19:54:16,917 INFO: Cluster mgmt job handle: {'job_id': 'wsjob-kzid8uvxjgp7i3yvarv34i', 'service_url': '10.253.20.16:443', 'service_authority': 'wsjob-kzid8uvxjgp7i3yvarv34i-coordinator-0.cluster-server.mb-systemf159.cerebras.com', 'credentials_path': '/opt/cerebras/certs/tls.crt'}
2023-04-25 19:54:16,920 INFO: Creating a framework GRPC client: 10.253.20.16:443, <grpc.ChannelCredentials object at 0x7ffe1c33f1d0>, wsjob-kzid8uvxjgp7i3yvarv34i-coordinator-0.cluster-server.mb-systemf159.cerebras.com
2023-04-25 19:54:17,004 INFO: Compile successfully written to cache directory: cs_14188819967248100901
2023-04-25 19:54:17,014 INFO: Compile for evaluation completed successfully!
2023-04-25 19:54:17,014 INFO: ClusterClient: server=10.253.20.16:443, authority=cluster-server.mb-systemf159.cerebras.com, cert=/opt/cerebras/certs/tls.crt
2023-04-25 19:54:17,015 INFO: Initiating a new execute wsjob against the cluster server.
2023-04-25 19:54:17,040 INFO: execute job id: wsjob-lzqvtr3vt7fv8atvuwowoc, log path: /cb/tests/cluster-mgmt/mb-systemf159/workdir/wsjob-lzqvtr3vt7fv8atvuwowoc
2023-04-25 19:54:27,052 INFO: Poll ingress status: Waiting for coordinator to be ready.
2023-04-25 19:55:07,098 INFO: Poll ingress status: Coordinator svc ready, poll ingress success.
2023-04-25 19:55:07,099 INFO: Ingress is ready.
2023-04-25 19:55:07,099 INFO: Cluster mgmt job handle: {'job_id': 'wsjob-lzqvtr3vt7fv8atvuwowoc', 'service_url': '10.253.20.16:443', 'service_authority': 'wsjob-lzqvtr3vt7fv8atvuwowoc-coordinator-0.cluster-server.mb-systemf159.cerebras.com', 'credentials_path': '/opt/cerebras/certs/tls.crt'}
2023-04-25 19:55:07,099 INFO: Removing a framework GRPC client: 10.253.20.16:443
2023-04-25 19:55:07,099 INFO: Creating a framework GRPC client: 10.253.20.16:443, <grpc.ChannelCredentials object at 0x7ffe1c024710>, wsjob-lzqvtr3vt7fv8atvuwowoc-coordinator-0.cluster-server.mb-systemf159.cerebras.com
2023-04-25 19:55:07,117 INFO: Preparing to execute using 1 CSX
2023-04-25 19:55:07,129 INFO: Monitoring Coordinator for Runtime server errors
2023-04-25 19:55:19,293 INFO: About to send initial weights
2023-04-25 19:55:32,292 INFO: Finished sending initial weights
2023-04-25 19:59:37,167 INFO: | Eval Device=CSX, Step=1, Loss=10.56250, Rate=2363.12 samples/sec, GlobalRate=2362.78 samples/sec
2023-04-25 19:59:37,168 INFO: Avg eval_metrics = {'eval/lm_perplexity': 37632.0, 'eval/accuracy': 0.037353515625}
2023-04-25 19:59:37,168 INFO: Avg Eval. Loss = 10.5625
2023-04-25 19:59:37,173 INFO: Evaluation completed successfully.
2023-04-25 19:59:37,173 INFO: Processed 120 sample(s) in 0.05668282508850098 seconds.
Evaluating the model fine-tuned from Cerebras-GPT#
To evaluate the fine-tuned model, run the run.py script associated with the GPT-3 models in the Cerebras Model Zoo. This is the same run.py script used during evaluating model trained from scratch, but you will change the following flag:
|
Specifies the model directory that contains the checkpoints from the fine-tuned model |
python models/nlp/gpt3/run.py \
CSX \
--params custom_config_GPT111M.yaml \
--num_csx=1 \
--model_dir finetune_GPT111M \
--mode eval_all \
--mount_dirs $PARENT_CS $PARENT_CS/modelzoo \
--python_paths $PARENT_CS/modelzoo
--job_labels model=eval_finetune_GPT111M
After the validation job is complete, you will find additional files inside the finetune_GPT_111M folder, including an eval folder that contains the metrics logged during the model evaluation and a new run_<data>_######.log with the command line output during model evaluation. Here is an example of the command line output.
2023-04-25 19:39:00,020 INFO: Loading weights from checkpoint finetune_GPT111M/checkpoint_10.mdl
2023-04-25 19:39:02,718 INFO: Compiling the model. This may take a few minutes.
2023-04-25 19:39:04,807 INFO: ClusterClient: server=10.253.20.16:443, authority=cluster-server.mb-systemf159.cerebras.com, cert=/opt/cerebras/certs/tls.crt
2023-04-25 19:39:04,822 INFO: Initiating a new compile wsjob against the cluster server.
2023-04-25 19:39:04,836 INFO: compile job id: wsjob-jkaa5xqkq6fa7qkettakcd, log path: /cb/tests/cluster-mgmt/mb-systemf159/workdir/wsjob-jkaa5xqkq6fa7qkettakcd
2023-04-25 19:39:14,846 INFO: Poll ingress status: Waiting for coordinator to be ready.
2023-04-25 19:39:24,852 INFO: Poll ingress status: Coordinator svc ready, poll ingress success.
2023-04-25 19:39:24,852 INFO: Ingress is ready.
2023-04-25 19:39:24,852 INFO: Cluster mgmt job handle: {'job_id': 'wsjob-jkaa5xqkq6fa7qkettakcd', 'service_url': '10.253.20.16:443', 'service_authority': 'wsjob-jkaa5xqkq6fa7qkettakcd-coordinator-0.cluster-server.mb-systemf159.cerebras.com', 'credentials_path': '/opt/cerebras/certs/tls.crt'}
2023-04-25 19:39:24,861 INFO: Creating a framework GRPC client: 10.253.20.16:443, <grpc.ChannelCredentials object at 0x7ffe1bf88190>, wsjob-jkaa5xqkq6fa7qkettakcd-coordinator-0.cluster-server.mb-systemf159.cerebras.com
2023-04-25 19:43:54,599 INFO: Compile successfully written to cache directory: cs_14188819967248100901
2023-04-25 19:43:54,625 INFO: Compile for evaluation completed successfully!
2023-04-25 19:43:54,625 INFO: ClusterClient: server=10.253.20.16:443, authority=cluster-server.mb-systemf159.cerebras.com, cert=/opt/cerebras/certs/tls.crt
2023-04-25 19:43:54,626 INFO: Initiating a new execute wsjob against the cluster server.
2023-04-25 19:43:54,655 INFO: execute job id: wsjob-fkerxr57pmw8sq2bxa7hgy, log path: /cb/tests/cluster-mgmt/mb-systemf159/workdir/wsjob-fkerxr57pmw8sq2bxa7hgy
2023-04-25 19:44:04,682 INFO: Poll ingress status: Waiting for coordinator to be ready.
2023-04-25 19:44:44,727 INFO: Poll ingress status: Coordinator svc ready, poll ingress success.
2023-04-25 19:44:44,727 INFO: Ingress is ready.
2023-04-25 19:44:44,727 INFO: Cluster mgmt job handle: {'job_id': 'wsjob-fkerxr57pmw8sq2bxa7hgy', 'service_url': '10.253.20.16:443', 'service_authority': 'wsjob-fkerxr57pmw8sq2bxa7hgy-coordinator-0.cluster-server.mb-systemf159.cerebras.com', 'credentials_path': '/opt/cerebras/certs/tls.crt'}
2023-04-25 19:44:44,728 INFO: Removing a framework GRPC client: 10.253.20.16:443
2023-04-25 19:44:44,728 INFO: Creating a framework GRPC client: 10.253.20.16:443, <grpc.ChannelCredentials object at 0x7ffe1bfbae10>, wsjob-fkerxr57pmw8sq2bxa7hgy-coordinator-0.cluster-server.mb-systemf159.cerebras.com
2023-04-25 19:44:44,746 INFO: Preparing to execute using 1 CSX
2023-04-25 19:44:44,761 INFO: Monitoring Coordinator for Runtime server errors
2023-04-25 19:44:58,143 INFO: About to send initial weights
2023-04-25 19:45:14,240 INFO: Finished sending initial weights
2023-04-25 19:49:15,781 INFO: | Eval Device=CSX, Step=1, Loss=3.76562, Rate=616.63 samples/sec, GlobalRate=616.61 samples/sec
2023-04-25 19:49:15,783 INFO: Avg eval_metrics = {'eval/lm_perplexity': 43.0, 'eval/accuracy': 0.353515625}
2023-04-25 19:49:15,783 INFO: Avg Eval. Loss = 3.765625
2023-04-25 19:49:15,786 INFO: Evaluation completed successfully.
2023-04-25 19:49:15,786 INFO: Processed 120 sample(s) in 0.19986581802368164 seconds.
Visualizing the results using TensorBoard#
Launch TensorBoard to visualize the metrics recorded during training and evaluation of the models. Make sure that the Cerebras virtual environment is active.
cd $PARENT_CS
tensorboard \
--logdir . \
--bind_all
TensorBoard 2.2.2 at http://<url-to-user-node>:6006/ (Press CTRL+C to quit)
Note
When hosting multiple TensorBoard instances concurrently, you may see the error Port 6006 is in use by another program. Either identify and stop that program, or start the server with a different port.. As a work around, you can launch TensorBoard by specifying a different port with the --port flag.
After launching TensorBoard, you will get a URL link to access the results in your local network.
Fig. 7 Metrics logged in GPT implementation in Cerebras Model Zoo#
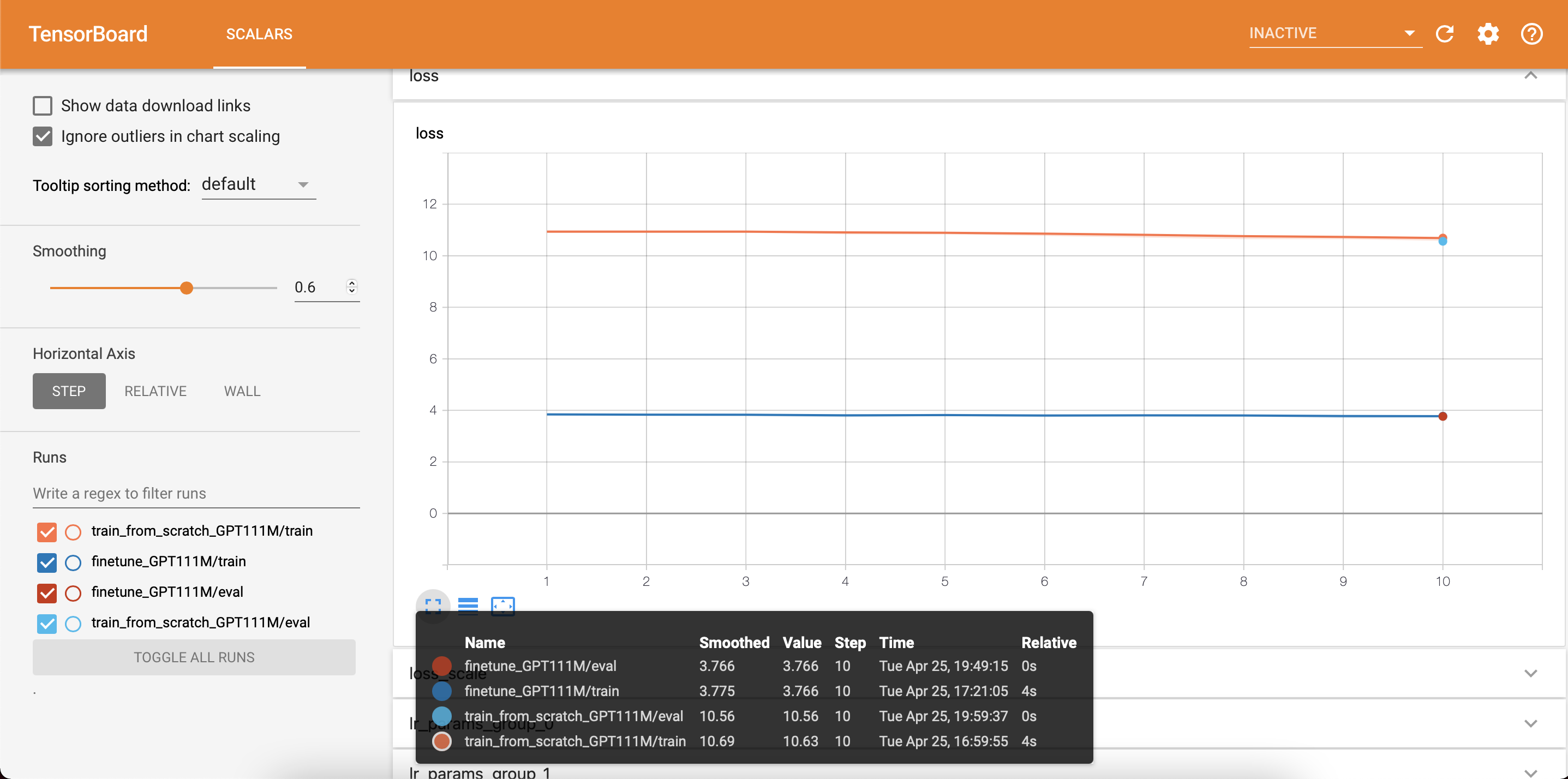
Fig. 8 Value of training and validation loss after 10 steps for model train from scratch (train_from_scratch_GPT111M) and fine-tuning from Cerebras-GPT checkpoint (finetune_GPT111M)#
What’s next?#
Now that you have trained and fine-tuned your GPT model in Cerebras’s Wafer-Scale Cluster, try porting your model to Hugging face to generate outputs. The Cerebras Model Zoo contains conversion scripts to convert from Cerebras Model Zoo to Hugging Face. For more information on conversion scripts, refer Convert checkpoints and model configs.
In addition, if you want to fine-tune your LLM model on a dataset using intstructions, refer to our How-To Instruction fine-tuning for LLMs.