How Cerebras Works
On This Page
How Cerebras Works#
Big picture#
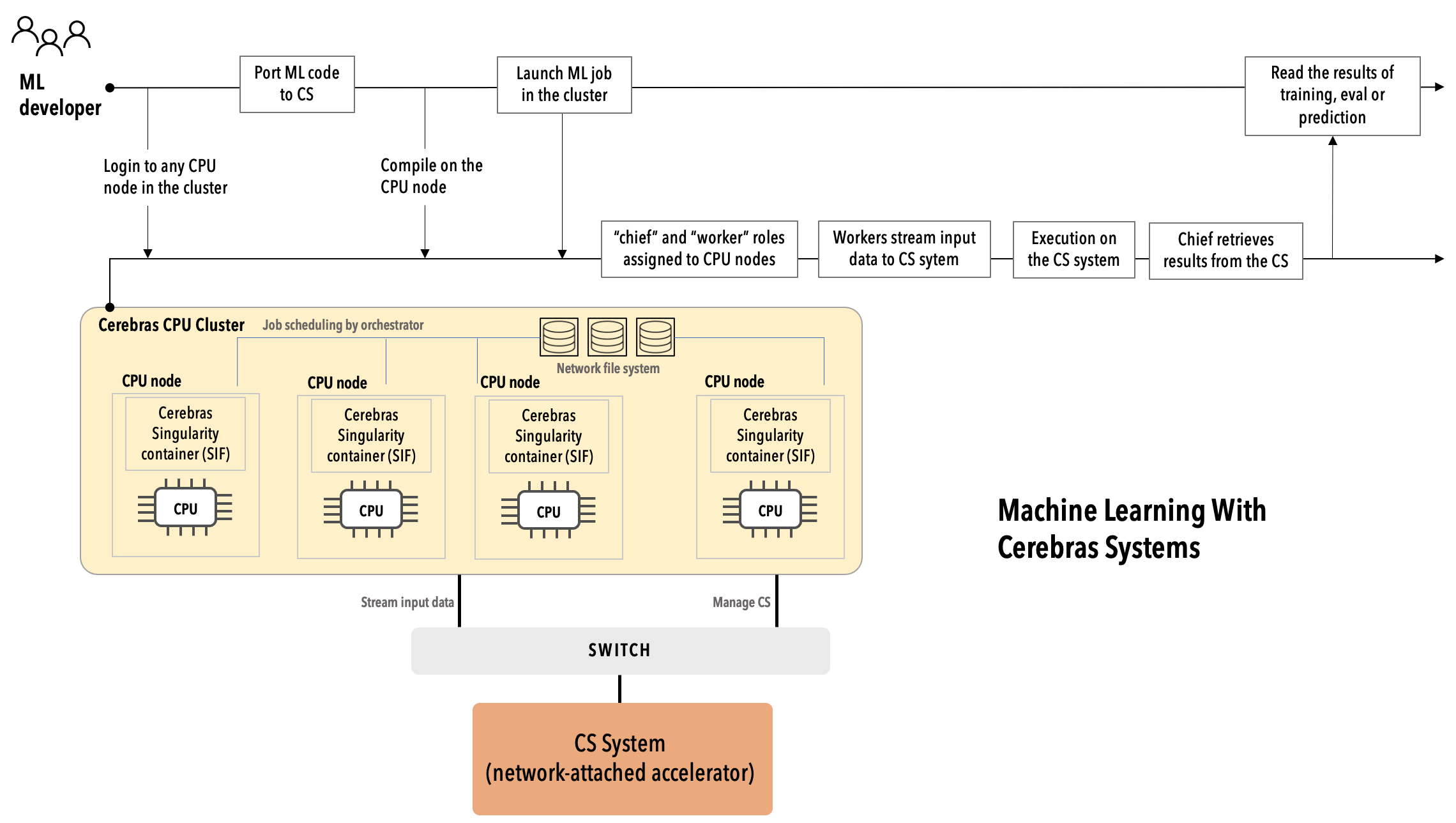
When the CS system is installed at your site, it will look similar to the following diagram (click on the image to enlarge it), with the network-attached Cerebras accelerator coexisting with a Cerebras server cluster. This section presents a big picture view of the Cerebras system and how a machine developer uses it.
Important
This documentation describes only how to use the already-installed CS system at your site. It does not present installation and administration instructions for your CS system.
As an ML developer you use the Cerebras system like this:
Using the login credentials provided by the system administrator, you log in to a CPU node in the Cerebras server cluster.
Port your existing TensorFlow or PyTorch ML code to Cerebras. For TensorFlow, use
CerebrasEstimator, and for PyTorch, usecerebras.framework.torch.Compile your code using the Cerebras Graph Compiler on the CPU node.
Make your input data ready on a network file system so it can be streamed at a very high speed to the Cerebras accelerator.
Run your compiled code on the CS system.
During runtime, the workers in the CPU cluster stream the input data to the Cerebras accelerator. When the execution is done, the chief retrieves the results from the network-attached accelerator for you to review.
Programming model#
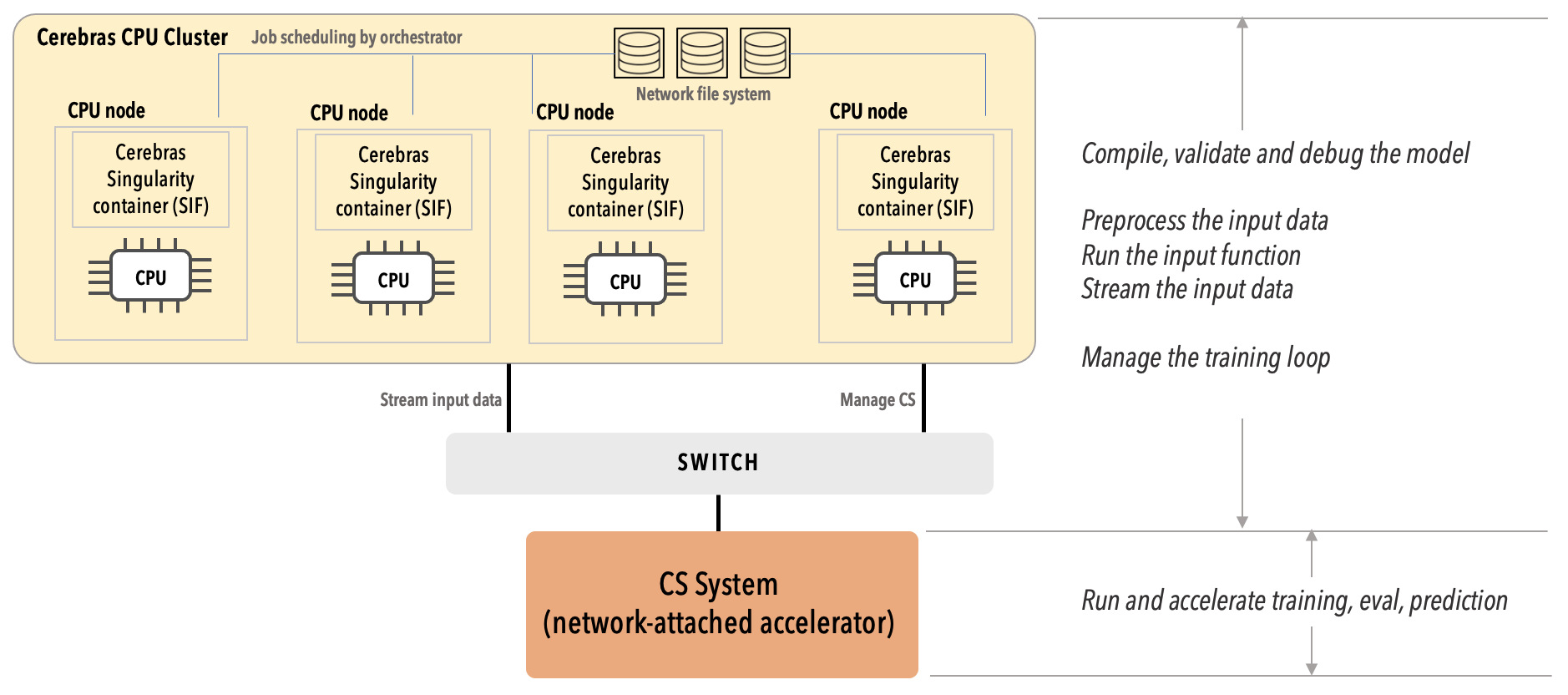
As shown in the following picture:
The CS system is responsible only for running and accelerating the actual training and predictions on the neural network.
All the supporting tasks, such as starting with the TensorFlow and PyTorch frameworks and compiling the model, preprocessing the input data, running the input function, streaming the data, and managing the training loop, are executed in the Cerebras server cluster by the Cerebras software running on these nodes.
Cerebras Graph Compiler#
The Cerebras Graph Compiler (CGC) compiles your ML code that is ported to Cerebras, that is, containing the CerebrasEstimator if TensorFlow and cerebras.framework.torch if PyTorch. When the compilation finishes, a binary file is generated and is sent to the CS system for execution.
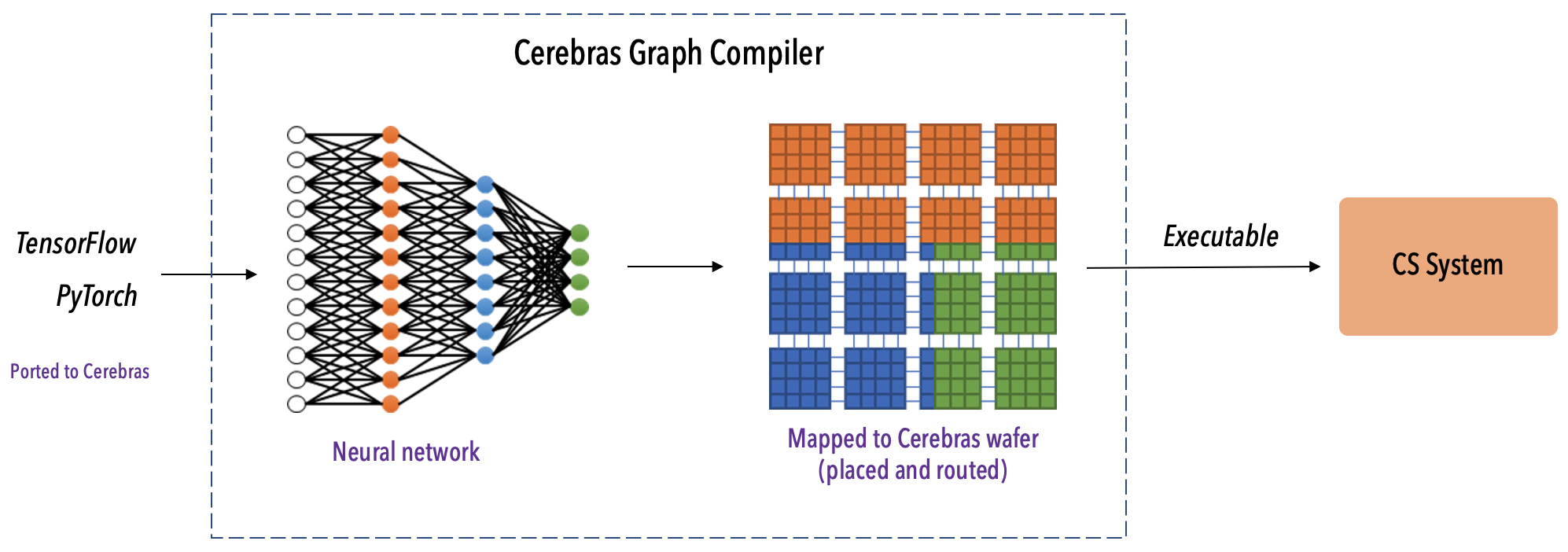
When the Cerebras Singularity SIF image is installed on all the chief and worker nodes, as a part of the standard Cerebras system set up by your system administrator, the CGC (“compiler”) is automatically installed on all these CPU nodes.
The Cerebras server cluster#
The Cerebras network-attached accelerator performs cluster-scale acceleration. For this reason, when you execute your neural network on the CS system, you must ensure that you stream the input data to the neural network at extreme high speeds. In other words, your input pipeline must be very fast. You can achieve high input data throughput by running the input pipeline on multiple CPU nodes simultaneously, all feeding the data to the CS system. This is accomplished with the Cerebras server cluster.
The Cerebras server cluster
The terms “Cerebras server cluster” and “Original Cerebras Support-Cluster” are synonymous, representing a cluster of CPU compute nodes attached to the Cerebras network-attached accelerator.
Cerebras multi-worker vs. GPU multi-worker#
Unlike a conventional GPU, which is directly connected to a host CPU, the CS system is connected to the cluster of CPU nodes over a network. See the following diagram:
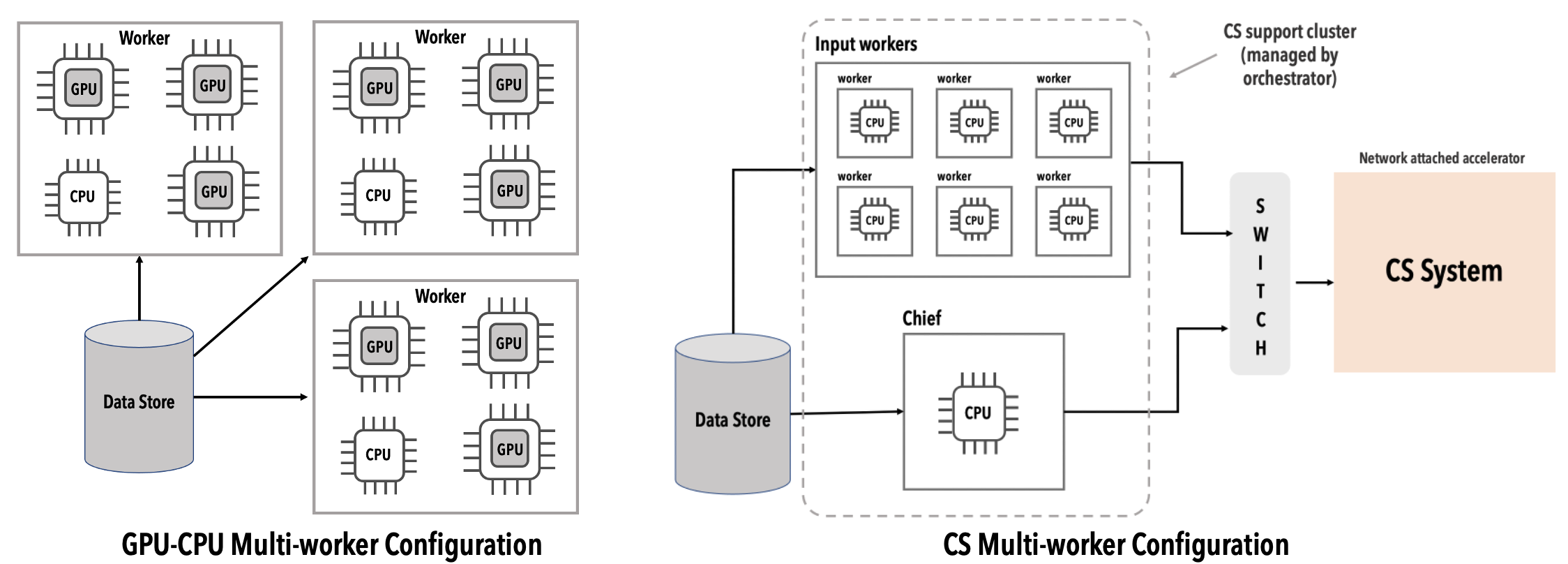
The ML developer accesses the CS system by specifying the IP address and the port number of the CS system.
Note
The default execution model for the CS system is a distributed, multi-worker model.
Chief and worker nodes#
During runtime, the CPU nodes in the Original Cerebras Support-Cluster are assigned two distinct roles: a single chief and multiple workers. See the following for a description of these roles.
In the CS system execution model, a CPU node is configured either as a chief node, or as a worker node. There is one chief node and one or more worker nodes.
- Chief
The chief node compiles the ML model into a Cerebras executable, and manages the initialization and training loop on the CS system. Usually one CPU node is assigned exclusively to the chief role.
- Worker
The worker node handles the input pipeline and the data streaming to the CS system. One or more CPU nodes are assigned as workers. You can scale worker nodes up or down to provide the desired input bandwidth.
Orchestrator#
The coordination between the CS system and the Original Cerebras Support-Cluster is performed by the orchestrator software Slurm that runs on the CPU nodes.
The Cerebras ML workflow#
Next, see The Cerebras ML Workflow for a detailed description of how the Cerebras ML workflow works. ���������������������������������������������