The run.py Template
On This Page
The run.py Template#
Whether you compile on a CPU node using the csrun_cpu script, or run on the Cerebras system using the csrun_wse script, you must pass a full Python command along with its command line arguments, as an argument to the script.
This section presents an example Python template run.py with a detailed description of the supported options and flags. Note that this applies to the pipeline workflow, not for weight streaming.
Note
The run.py described below is an example template only. If you are developing in TensorFlow, you can organize your code whichever way that best suits you, as long as you use CerebrasEstimator. If you are developing in PyTorch you can use the run function, common to all implementations in the Cerebras Model Zoo git repository. You can find more about the run function in the adapting-pytorch-to-cs document.
For TensorFlow code, see the following diagram showing a simplified run.py example using the CerebrasEstimator and the CGC flow.
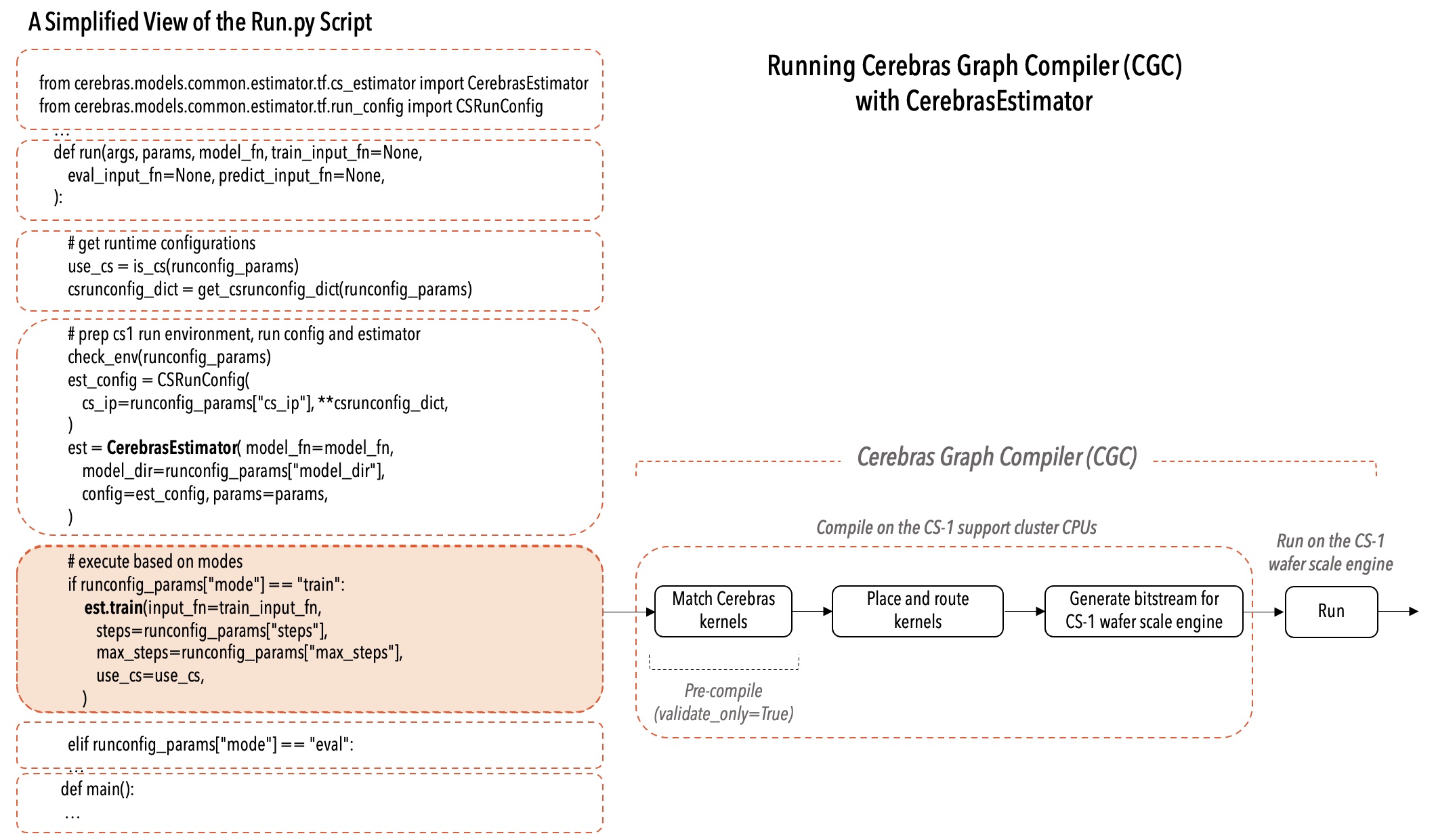
Fig. 2 Cerebras Graph Compiler for the CS system#
Syntax#
python run.py -p --params <PATH-TO-YAML-FILE> \
-o --model_dir <PATH-TO-MODEL-DIR> \
--cs_ip <CS system-IP-ADDRESS> \
--steps <INTEGER> \
--max_steps <INTEGER> \
-m --mode <MODE-TO-RUN> \
--compile_only \
--device <SPECIFY-DEVICE-TO-RUN-ON> \
--checkpoint_path <INITIALIZE WEIGHTS FROM> \
where:
Arguments#
params#
-p --params: Required. String. Path to the YAML file that contains the model parameters.For example:
--params configs/params_bert_base_msl512.yaml.
model_dir#
-o --model_dir: Optional. String. The location where your model and all the outputs such as checkpoints and event files are stored. If the directory exists, then the weights are loaded from the checkpoint file. Same as themodel_dirpassed to thetf.estimator. Default value is current directory of execution. See also tf.estimator.Estimator.
cs_ip#
--cs_ip: Optional. The IP address of the CS system. Format should beIP-ADDRESS:PORT. Default value isNone. This option is ignored on GPU.
steps#
--steps: Optional. Integer. The number of steps to run thetrainmode. Runs for the specified number of steps either while starting from the beginning or while continuing from a checkpoint. Default value isNone.
max_steps#
--max_steps: Optional. Integer. The total number of steps to run thetrainmode, or for training in thetrain_and_evalmode. If the run is continuing from a checkpoint that was made at or aftermax_steps, then the run will stop. If the run is continuing from a checkpoint that was made at less thanmax_steps, then it will run for the number of steps remaining between the checkpoint and themax_steps. Default value isNone.
eval_steps#
--eval_steps: Integer. Optional on the GPU but required when running on the CS system. The total number of steps to runevaloreval_allmodes, or for evaluation intrain_and_evalmode. Runs once for the specified number.
mode#
-m --mode: Required. String. Set the mode for your neural network. Allowed choices are:train: In this mode the compiler will compile, and run the training on the CS system. Ifcs_ipis not specified, then runs the training on the CPU or GPU.eval: In this mode the evaluation will run on CPU or GPU. For some neural network models, this is experimentally supported on the CS system.eval_all: In this mode the evaluation will run on CPU or GPU for all the available checkpoints. This mode is not yet supported on the CS system.train_and_eval: In this mode the training and evaluation will be run on CPU or GPU.predict: In this mode the prediction (inference) will run on CPU or GPU. For some neural network models, this is experimentally supported on the CS system.
compilation flags#
--validate_only: In this mode the compiler will stop after the kernel matching phase. Available in Pipelined execution mode for TensorFlow.
--compile_only: In this mode the compiler will continue after the kernel matching until it finishes. If the compile is successful it will generate the CS system bitstream. Available in Pipelined execution mode.
device#
--device: Optional. String. This option should be used only to specify a GPU device. The compiler will compile on CPU, and will run on the GPU device specified in this setting.For example,
--device /gpu:0will run on the GPU 0.
checkpoint_path#
--checkpoint_path: Optional. String. The weights are initialized from the checkpoint specified with this option. Default value isNone. If this option is used with an initial checkpoint, and if themodel_diralready contains a checkpoint, then the compiler will alert you to:Either provide an empty
model_dirso the weights are initialized using the value provided to thischeckpoint_pathoption, orRemove this option
checkpoint_pathin order to initialize weights from themodel_dir.
Example: BERT run.py#
Shown below is the run.py example code of the BERT model.
1 # Example run.py script for BERT
2
3 # Copyright 2021 Cerebras Systems.
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16
17 import argparse
18 import os
19 import sys
20
21 import tensorflow as tf
22
23 # Relative path imports
24 sys.path.append(os.path.join(os.path.dirname(__file__), '../../..'))
25 from common_zoo.estimator.tf.cs_estimator import CerebrasEstimator
26 from common_zoo.estimator.tf.run_config import CSRunConfig
27 from common_zoo.run_utils import (
28 check_env,
29 create_warm_start_settings,
30 get_csconfig,
31 get_csrunconfig_dict,
32 is_cs,
33 save_params,
34 save_predictions,
35 update_params_from_args,
36 )
37 from transformers.bert.tf.data import eval_input_fn, train_input_fn
38 from transformers.bert.tf.model import model_fn
39 from transformers.bert.tf.utils import get_params
40
41
42 def create_arg_parser(default_model_dir):
43 """
44 Create parser for command line args.
45
46 :param str default_model_dir: default value for the model_dir
47 :returns: ArgumentParser
48 """
49 parser = argparse.ArgumentParser()
50 parser.add_argument(
51 "-p",
52 "--params",
53 required=True,
54 help="Path to .yaml file with model parameters",
55 )
56 parser.add_argument(
57 "-o",
58 "--model_dir",
59 default=default_model_dir,
60 help="Model directory where checkpoints will be written. "
61 + "If directory exists, weights are loaded from the checkpoint file.",
62 )
63 parser.add_argument(
64 "--cs_ip",
65 default=None,
66 help="CS system IP address, defaults to None. Ignored on GPU.",
67 )
68 parser.add_argument(
69 "--steps",
70 type=int,
71 default=None,
72 help=(
73 "Number of steps to run mode train."
74 + " Runs repeatedly for the specified number."
75 ),
76 )
77 parser.add_argument(
78 "--max_steps",
79 type=int,
80 default=None,
81 help=(
82 "Number of total steps to run mode train or for defining training"
83 + " configuration for train_and_eval. Runs incrementally till"
84 + " the specified number."
85 ),
86 )
87 parser.add_argument(
88 "--eval_steps",
89 type=int,
90 default=None,
91 help=(
92 "Number of total steps to run mode eval, eval_all or for defining"
93 + " eval configuration for train_and_eval. Runs once for"
94 + " the specified number."
95 ),
96 )
97 parser.add_argument(
98 "-m",
99 "--mode",
100 required=True,
101 choices=["train", "eval", "eval_all", "train_and_eval", "predict",],
102 help=(
103 "Can train, eval, eval_all, train_and_eval, or predict."
104 + " Train, eval, and predict will compile and train if on CS system,"
105 + " and just run locally (CPU/GPU) if not on CS system."
106 + " train_and_eval will run locally."
107 + " Eval_all will run eval locally for all available checkpoints."
108 ),
109 )
110 parser.add_argument(
111 "--validate_only",
112 action="store_true",
113 help="Compile model up to kernel matching.",
114 )
115 parser.add_argument(
116 "--compile_only",
117 action="store_true",
118 help="Compile model completely, generating compiled executables.",
119 )
120 parser.add_argument(
121 "--device",
122 default=None,
123 help="Force model to run on a specific device (e.g., --device /gpu:0)",
124 )
125 parser.add_argument(
126 "--checkpoint_path",
127 default=None,
128 help="Checkpoint to initialize weights from.",
129 )
130
131 return parser
132
133
134 def validate_runtime_params(params):
135 # check validate_only/compile_only
136 assert not (
137 params["validate_only"] and params["compile_only"]
138 ), "Please only use one of validate_only and compile_only."
139 if params["validate_only"] or params["compile_only"]:
140 assert params["mode"] in [
141 "train",
142 "eval",
143 "predict",
144 ], "Can only validate/compile model in train, eval, or predict mode."
145
146 # check for gpu optimization flags
147 if (
148 params["mode"] not in ["compile_only", "validate_only"]
149 and not is_cs(params)
150 and not params["enable_gpu_optimizations"]
151 ):
152 tf.compat.v1.logging.warn(
153 "Set enable_gpu_optimizations to True in training params "
154 "to improve GPU performance."
155 )
156
157
158 def run(
159 args,
160 params,
161 model_fn,
162 train_input_fn=None,
163 eval_input_fn=None,
164 predict_input_fn=None,
165 output_layer_name=None,
166 ):
167 """
168 Set up estimator and run based on mode
169
170 :params dict params: dict to handle all parameters
171 :params tf.estimator.EstimatorSpec model_fn: Model function to run with
172 :params tf.data.Dataset train_input_fn: Dataset to train with
173 :params tf.data.Dataset eval_input_fn: Dataset to validate against
174 :params tf.data.Dataset predict_input_fn: Dataset to run inference on
175 :params str output_layer_name: name of the output layer to be excluded
176 from weight initialization when performing fine-tuning.
177 """
178 # update and validate runtime params
179 runconfig_params = params["runconfig"]
180 update_params_from_args(args, runconfig_params)
181 validate_runtime_params(runconfig_params)
182 # save params for reproducibility
183 save_params(params, model_dir=runconfig_params["model_dir"])
184
185 # get cs-specific configs
186 cs_config = get_csconfig(params.get("csconfig", dict()))
187 # get runtime configurations
188 use_cs = is_cs(runconfig_params)
189 csrunconfig_dict = get_csrunconfig_dict(runconfig_params)
190
191 stack_params = dict()
192 if (
193 use_cs
194 or runconfig_params["validate_only"]
195 or runconfig_params["compile_only"]
196 ):
197 from cerebras.pb.stack.full_pb2 import FullConfig
198
199 config = FullConfig()
200 if params['train_input']['max_sequence_length'] <= 128:
201 config.matching.kernel.no_dcache_spill_splits = True
202 stack_params['config'] = config
203
204 # prep cs1 run environment, run config and estimator
205 check_env(runconfig_params)
206 est_config = CSRunConfig(
207 cs_ip=runconfig_params["cs_ip"],
208 cs_config=cs_config,
209 stack_params=stack_params,
210 **csrunconfig_dict,
211 )
212 warm_start_settings = create_warm_start_settings(
213 runconfig_params, exclude_string=output_layer_name
214 )
215 est = CerebrasEstimator(
216 model_fn=model_fn,
217 model_dir=runconfig_params["model_dir"],
218 config=est_config,
219 params=params,
220 warm_start_from=warm_start_settings,
221 )
222
223 # execute based on mode
224 if runconfig_params["validate_only"] or runconfig_params["compile_only"]:
225 if runconfig_params["mode"] == "train":
226 input_fn = train_input_fn
227 mode = tf.estimator.ModeKeys.TRAIN
228 elif runconfig_params["mode"] == "eval":
229 input_fn = eval_input_fn
230 mode = tf.estimator.ModeKeys.EVAL
231 else:
232 input_fn = predict_input_fn
233 mode = tf.estimator.ModeKeys.PREDICT
234 est.compile(
235 input_fn, validate_only=runconfig_params["validate_only"], mode=mode
236 )
237 elif runconfig_params["mode"] == "train":
238 est.train(
239 input_fn=train_input_fn,
240 steps=runconfig_params["steps"],
241 max_steps=runconfig_params["max_steps"],
242 use_cs=use_cs,
243 )
244 elif runconfig_params["mode"] == "eval":
245 est.evaluate(
246 input_fn=eval_input_fn,
247 checkpoint_path=runconfig_params["checkpoint_path"],
248 steps=runconfig_params["eval_steps"],
249 use_cs=use_cs,
250 )
251 elif runconfig_params["mode"] == "eval_all":
252 ckpt_list = tf.train.get_checkpoint_state(
253 runconfig_params["model_dir"]
254 ).all_model_checkpoint_paths
255 for ckpt in ckpt_list:
256 est.evaluate(
257 eval_input_fn,
258 checkpoint_path=ckpt,
259 steps=runconfig_params["eval_steps"],
260 use_cs=use_cs,
261 )
262 elif runconfig_params["mode"] == "train_and_eval":
263 train_spec = tf.estimator.TrainSpec(
264 input_fn=train_input_fn, max_steps=runconfig_params["max_steps"]
265 )
266 eval_spec = tf.estimator.EvalSpec(
267 input_fn=eval_input_fn,
268 steps=runconfig_params["eval_steps"],
269 throttle_secs=runconfig_params["throttle_secs"],
270 )
271 tf.estimator.train_and_evaluate(est, train_spec, eval_spec)
272 elif runconfig_params["mode"] == "predict":
273 sys_name = "cs" if use_cs else "tf"
274 file_to_save = f"predictions_{sys_name}_{est_config.task_id}.npz"
275 predictions = est.predict(
276 input_fn=predict_input_fn,
277 checkpoint_path=runconfig_params["checkpoint_path"],
278 num_samples=runconfig_params["predict_steps"],
279 use_cs=use_cs,
280 )
281 save_predictions(
282 model_dir=runconfig_params["model_dir"],
283 outputs=predictions,
284 name=file_to_save,
285 )
286
287
288 def main():
289 """
290 Main function
291 """
292 default_model_dir = os.path.join(
293 os.path.dirname(os.path.abspath(__file__)), "model_dir"
294 )
295 parser = create_arg_parser(default_model_dir)
296 args = parser.parse_args(sys.argv[1:])
297 params = get_params(args.params)
298 run(
299 args=args,
300 params=params,
301 model_fn=model_fn,
302 train_input_fn=train_input_fn,
303 eval_input_fn=eval_input_fn,
304 )
305
306
307 if __name__ == "__main__":
308 tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.INFO)
309 main()